检索增强生成(RAG)
大型语言模型(LLM)虽然强大,但有两个关键限制:
- 有限的上下文——它们无法一次性摄取整个语料库
- 静态知识——它们的训练数据在某个时间点被冻结
检索通过在查询时获取相关的外部知识来解决这些问题。这是**检索增强生成(RAG)**的基础:使用特定上下文的信息来增强 LLM 的回答。
构建知识库
知识库是用于检索的文档或结构化数据的存储库。
如果你需要自定义知识库,可以使用 Spring AI Alibaba 的文档加载器和向量存储从你自己的数据构建。
如果你已经有一个知识库(例如 SQL 数据库、CRM 或内部文档系统),你不需要重建它。你可以:
- 将其连接为 Agent 的工具用于 Agentic RAG
- 查询它并将检索�到的内容作为上下文提供给 LLM(两步 RAG)
从检索到 RAG
检索允许 LLM 在运行时访问相关上下文。但大多数实际应用更进一步:它们将检索与生成集成以产生基于事实的、上下文感知的答案。
这是**检索增强生成(RAG)**的核心思想。检索管道成为结合搜索和生成的更广泛系统的基础。
检索流程
典型的检索工作流如下:

每个组件都是模块化的:你可以交换加载器、分割器、嵌入或向量存储,而无需重写应用程序的逻辑。
构建模块
在 Spring AI Alibaba 中,你可以使用以下组件构建 RAG 系统:
文档加载器和解析器
从外部源(文件、数据库、云存储、在线平台等)摄取数据,返回标准化的文档对象。Spring AI Alibaba 提供了丰富的 Document Reader 和 Document Parser 实现,支持 PDF、Word、Markdown、GitHub、Notion、语雀等多种数据源和格式。
文本分割器
将大型文档分解为更小的块,这些块可以单独检索并适合模型的上下文窗口。文本分割是 ETL 管道中的关键步骤,详见 ETL Pipeline。
嵌入模型
嵌入模型将文本转换为数字向量,使得具有相似含义的文本在向量空间中靠近在一起。Spring AI Alibaba 支持多种 Embedding Model 实现,包括 DashScope、OpenAI、Ollama 等。
向量存储
用于存储和搜索嵌入的专用数据库。Spring AI Alibaba 支持多种向量数据库,包括 Milvus、Pinecone、Redis、Elasticsearch 等。更多实现请查看 向量数据库文档。
检索器
检索器是一个接口,给定非结构化查询返回文档。Spring AI 提供了模块化的 RAG 架构,支持查询转换、查询扩展、文档后处理等高级功能,详见 Retrieval Augmented Generation。
RAG 架构
RAG 可以以多种方式实现,具体取决于你的系统需求。我们在下面的部分概述每种类型。
| 架构 | 描述 | 控制性 | 灵活性 | 延迟 | 使用场景示例 |
|---|---|---|---|---|---|
| 两步 RAG | 检索总是在生成之前发生。简单且可预测 | ✅ 高 | ❌ 低 | ⚡ 快 | FAQ、文档机器人 |
| Agentic RAG | LLM 驱动的 Agent 决定何时以及如何在推理过程中检索 | ❌ 低 | ✅ 高 | ⏳ 可变 | 具有多工具访问的研究助手 |
| 混合 RAG | 结合两种方法的特点,包含验证步骤 | ⚖️ 中 | ⚖️ 中 | ⏳ 可变 | 带质量验证的领域特定问答 |
延迟:延迟在两步 RAG中通常更可预测,因为 LLM 调用的最大次数是已知且有上限的。这种可预测性假设 LLM 推理时间是主要因素。但是,实际延迟也可能受检索步骤性能的影响——例如 API 响应时间、网络延迟或数据库查询——这些可能因使用的工具和基础设施而异。
两步 RAG
在两步 RAG中,检索步骤总是在生成步骤之前执行。这种架构简单且可预测,适合许多应用,其中检索相关文档是生成答案的明确前提。

Spring AI 提供了开箱即用的 QuestionAnswerAdvisor 和 RetrievalAugmentationAdvisor,简化两步 RAG 的实现。这些 Advisor 自动处理检索和上下文增强,详见 Retrieval Augmented Generation。
使用 MessagesModelHook 实现
通过 MessagesModelHook 在模型调用前检索文档并添加到消息中:
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import com.alibaba.cloud.ai.graph.agent.hook.messages.MessagesModelHook;
import com.alibaba.cloud.ai.graph.agent.hook.messages.AgentCommand;
import com.alibaba.cloud.ai.graph.agent.hook.messages.UpdatePolicy;
import com.alibaba.cloud.ai.graph.agent.hook.HookPosition;
import com.alibaba.cloud.ai.graph.agent.hook.HookPositions;
import com.alibaba.cloud.ai.graph.RunnableConfig;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.messages.AssistantMessage;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
// 假设你已经有一个配置好的向量存储
VectorStore vectorStore = ...; // 配置你的向量存储(如Milvus、Pinecone等)
// 创建 RAG Hook:在模型调用前检索文档并添加到消息中
@HookPositions({HookPosition.BEFORE_MODEL})
class RAGMessagesHook extends MessagesModelHook {
private final VectorStore vectorStore;
private static final int TOP_K = 5;
public RAGMessagesHook(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public String getName() {
return "rag_messages_hook";
}
@Override
public AgentCommand beforeModel(List<Message> previousMessages, RunnableConfig config) {
// 从消息中提取用户问题
String userQuestion = extractUserQuestion(previousMessages);
if (userQuestion == null || userQuestion.isEmpty()) {
return new AgentCommand(previousMessages);
}
// Step 1: 检索相关文档
List<Document> relevantDocs = vectorStore.similaritySearch(
org.springframework.ai.vectorstore.SearchRequest.builder()
.query(userQuestion)
.topK(TOP_K)
.build()
);
// Step 2: 构建上下文
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
// Step 3: 构建增强的消息列表
List<Message> enhancedMessages = new ArrayList<>();
// 添加系统提示(包含检索到的上下文)
String systemPrompt = String.format("""
你是一个有用的助手。基于以下上下文回答问题。
如果上下文中没有相关信息,请说明你不知道。
上下文:
%s
""", context);
enhancedMessages.add(new SystemMessage(systemPrompt));
// 保留原有的消息
enhancedMessages.addAll(previousMessages);
// 使用 REPLACE 策略替换消息
return new AgentCommand(enhancedMessages, UpdatePolicy.REPLACE);
}
private String extractUserQuestion(List<Message> messages) {
// 从消息列表中提取最后一个用户消息
for (int i = messages.size() - 1; i >= 0; i--) {
Message msg = messages.get(i);
if (msg instanceof UserMessage) {
return ((UserMessage) msg).getText();
}
}
return null;
}
}
// 创建带有 RAG Hook 的 Agent
ReactAgent ragAgent = ReactAgent.builder()
.name("rag_agent")
.model(chatModel)
.hooks(new RAGMessagesHook(vectorStore))
.build();
// 调用 Agent
AssistantMessage response = ragAgent.call("Spring AI Alibaba支持哪些模型?");
System.out.println("答案: " + response.getText());
使用 ModelInterceptor 实现
通过 ModelInterceptor 检索文档后附加到 systemPrompt:
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelInterceptor;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelRequest;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelResponse;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelCallHandler;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.chat.messages.SystemMessage;
import java.util.List;
import java.util.stream.Collectors;
// 假设你已经有一个配置好的向量存储
VectorStore vectorStore = ...; // 配置你的向量存储(如Milvus、Pinecone等)
// 创建 RAG Interceptor:检索文档后附加到 systemPrompt
class RAGModelInterceptor extends ModelInterceptor {
private final VectorStore vectorStore;
private static final int TOP_K = 5;
public RAGModelInterceptor(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 从用户消息中提取查询
String userQuery = extractUserQuery(request);
if (userQuery == null || userQuery.isEmpty()) {
return handler.call(request);
}
// Step 1: 检索相关文档
List<Document> relevantDocs = vectorStore.similaritySearch(
org.springframework.ai.vectorstore.SearchRequest.builder()
.query(userQuery)
.topK(TOP_K)
.build()
);
// Step 2: 构建上下文
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
// Step 3: 增强 systemPrompt
String enhancedSystemPrompt = String.format("""
你是一个有用的助手。基于以下上下文回答问题。
如果上下文中没有相关信息,请说明你不知道。
上下文:
%s
""", context);
// 合并原有的 systemPrompt 和检索到的上下文
SystemMessage enhancedSystemMessage;
if (request.getSystemMessage() == null) {
enhancedSystemMessage = new SystemMessage(enhancedSystemPrompt);
} else {
enhancedSystemMessage = new SystemMessage(
request.getSystemMessage().getText() + "
" + enhancedSystemPrompt
);
}
// 创建增强的请求
ModelRequest enhancedRequest = ModelRequest.builder(request)
.systemMessage(enhancedSystemMessage)
.build();
// 调用处理器
return handler.call(enhancedRequest);
}
private String extractUserQuery(ModelRequest request) {
// 从消息列表中提取用户查询
return request.getMessages().stream()
.filter(msg -> msg instanceof org.springframework.ai.chat.messages.UserMessage)
.map(msg -> ((org.springframework.ai.chat.messages.UserMessage) msg).getText())
.reduce((first, second) -> second) // 获取最后一个用户消息
.orElse("");
}
@Override
public String getName() {
return "rag_model_interceptor";
}
}
// 创建带有 RAG Interceptor 的 Agent
ReactAgent ragAgent = ReactAgent.builder()
.name("rag_agent")
.model(chatModel)
.interceptors(new RAGModelInterceptor(vectorStore))
.build();
// 调用 Agent
AssistantMessage response = ragAgent.call("Spring AI Alibaba支持哪些模型?");
System.out.println("答案: " + response.getText());
使用 AgentHook 实现(只检索一次)
如果不想在每次 Agent reasoning 循环中都检索 RAG,可以使用 AgentHook 在 Agent 开始时只检索一次,然后将检索结果存储到状态中供后续使用:
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import com.alibaba.cloud.ai.graph.agent.hook.AgentHook;
import com.alibaba.cloud.ai.graph.agent.hook.HookPosition;
import com.alibaba.cloud.ai.graph.agent.hook.HookPositions;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelInterceptor;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelRequest;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelResponse;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelCallHandler;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.RunnableConfig;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.chat.messages.SystemMessage;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
import java.util.stream.Collectors;
// 假设你已经有一个配置好的向量存储
VectorStore vectorStore = ...; // 配置你的向量存储(如Milvus、Pinecone等)
// 在 Agent 开始时检索文档(只执行一次)
@HookPositions({HookPosition.BEFORE_AGENT})
class RAGAgentHook extends AgentHook {
private final VectorStore vectorStore;
private static final int TOP_K = 5;
private static final String RAG_CONTEXT_KEY = "rag_context";
public RAGAgentHook(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@Override
public String getName() {
return "rag_agent_hook";
}
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// 从状态中提取用户问题
Optional<Object> messagesOpt = state.value("messages");
if (messagesOpt.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
@SuppressWarnings("unchecked")
List<org.springframework.ai.chat.messages.Message> messages =
(List<org.springframework.ai.chat.messages.Message>) messagesOpt.get();
// 提取最后一个用户消息作为查��询
String userQuery = messages.stream()
.filter(msg -> msg instanceof org.springframework.ai.chat.messages.UserMessage)
.map(msg -> ((org.springframework.ai.chat.messages.UserMessage) msg).getText())
.reduce((first, second) -> second) // 获取最后一个
.orElse("");
if (userQuery.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
// Step 1: 检索相关文档(只执行一次,在整个 Agent 执行过程中)
List<Document> relevantDocs = vectorStore.similaritySearch(
org.springframework.ai.vectorstore.SearchRequest.builder()
.query(userQuery)
.topK(TOP_K)
.build()
);
// Step 2: 构建上下文
String context = relevantDocs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
config.metadata().ifPresent(meta -> {
meta.put(RAG_CONTEXT_KEY, context);
});
// Step 3: 将检索到的上下文存储到状态中,供后续 ModelInterceptor 使用
// 存储到 state 中,ModelInterceptor 可以通过 request.getContext() 访问
return CompletableFuture.completedFuture(Map.of());
}
}
// 在模型调用时使用存储的上下文
class RAGContextInterceptor extends ModelInterceptor {
private static final String RAG_CONTEXT_KEY = "rag_context";
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 从请求上下文中获取检索到的 RAG 上下文
// RAG 上下文在 AgentHook 的 beforeAgent 中已经存储到状态中
Map<String, Object> context = request.getContext();
String ragContext = (String) context.get(RAG_CONTEXT_KEY);
if (ragContext == null || ragContext.isEmpty()) {
// 如果没有检索到上下文,直接调用处理器
return handler.call(request);
}
// 增强 systemPrompt
String enhancedSystemPrompt = String.format("""
你是一个有用的助手。基于以下上下文回答问题。
如果上下文中没有相关信息,请说明你不知道。
上下文:
%s
""", ragContext);
// 合并原有的 systemPrompt 和检索到的上下文
SystemMessage enhancedSystemMessage;
if (request.getSystemMessage() == null) {
enhancedSystemMessage = new SystemMessage(enhancedSystemPrompt);
} else {
enhancedSystemMessage = new SystemMessage(
request.getSystemMessage().getText() + "
" + enhancedSystemPrompt
);
}
// 创建增强的请求
ModelRequest enhancedRequest = ModelRequest.builder(request)
.systemMessage(enhancedSystemMessage)
.build();
return handler.call(enhancedRequest);
}
@Override
public String getName() {
return "rag_context_interceptor";
}
}
// 创建带有 RAG Hook 和 Interceptor 的 Agent
ReactAgent ragAgent = ReactAgent.builder()
.name("rag_agent")
.model(chatModel)
.hooks(new RAGAgentHook(vectorStore))
.interceptors(new RAGContextInterceptor())
.build();
// 调用 Agent(RAG 检索只会在 Agent 开始时执行一次)
AssistantMessage response = ragAgent.call("Spring AI Alibaba支持哪些模型?");
System.out.println("答案: " + response.getText());
三种方式对比:
| 方式 | 执行时机 | 检索次数 | 适用场景 |
|---|---|---|---|
| MessagesModelHook | 每次模型调用前 | 每次 reasoning 循环 | 需要根据每次推理动态检索 |
| ModelInterceptor | 每次模型调用前 | 每次 reasoning 循环 | 需要访问完整请求信息 |
| AgentHook | Agent 开始时 | 只检索一次 | 优化性能,避免重复检索 |
选择建议:
- 如果查询在 Agent 执行过程中不会变化,使用 AgentHook 可以显著提升性能
- 如果需要根据每次推理的结果动态调整检索,使用 MessagesModelHook 或 ModelInterceptor
所有方式都能实现两步 RAG:检索文档 → 增强上下文 → 生成答案。
构建知识库
使用 ETL 管道(Extract、Transform、Load)可以轻松构建知识库。Spring AI 提供了统一的 ETL 接口,支持链式处理:
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import java.util.List;
// 1. 加载文档
Resource resource = new FileSystemResource("path/to/document.txt");
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
// 2. 分割文档为块
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> chunks = splitter.apply(documents);
// 3. 将块添加到向量存储
vectorStore.add(chunks);
// 现在你可以使用向量存储进行检索
List<Document> results = vectorStore.similaritySearch("查询文本");
更多关于 ETL 管道的详细说明和高级用法,请参考 ETL Pipeline 文档。
Agentic RAG
Agentic 检索增强生成(RAG)将检索增强生成的优势与基于 Agent 的推理相结合。Agent(由 LLM 驱动)不是在回答之前检索文档,而是逐步推理并决定在交互过程中何时以及如何检索信息。
Agent 启用 RAG 行为所需的唯一条件是访问一个或多个可以获取外部知识的工具——例如文档加载器、Web API 或数据库查询。
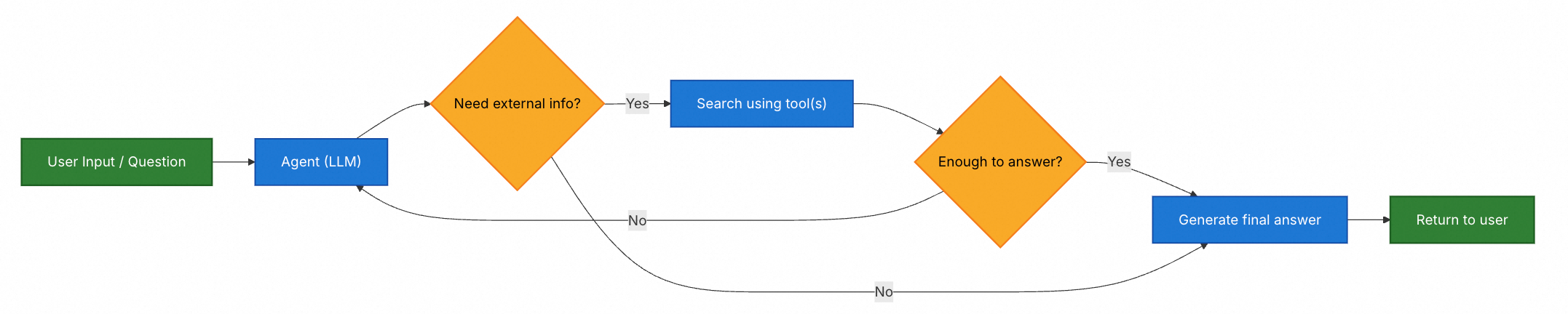
Java 实现示例
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import org.springframework.ai.document.Document;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.ai.tool.function.FunctionToolCallback;
import org.springframework.ai.vectorstore.VectorStore;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
// 创建文档检索工具
class DocumentSearchTool {
private final VectorStore vectorStore;
public DocumentSearchTool(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public record Request(String query) {}
public record Response(String content) {}
public Response search(Request request) {
// 从向量存储检索相关文档
List<Document> docs = vectorStore.similaritySearch(request.query());
// 合并文档内容
String combinedContent = docs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
return new Response(combinedContent);
}
}
DocumentSearchTool searchTool = new DocumentSearchTool(vectorStore);
// 创建工具回调
ToolCallback searchCallback = FunctionToolCallback.builder("search_documents",
(Function<DocumentSearchTool.Request, DocumentSearchTool.Response>)
request -> searchTool.search(request))
.description("搜索文档以查找相关信息")
.inputType(DocumentSearchTool.Request.class)
.build();
// 创建带有检索工具的Agent
ReactAgent ragAgent = ReactAgent.builder()
.name("rag_agent")
.model(chatModel)
.instruction("你是一个智能助手。当需要查找信息时,使用search_documents工具。" +
"基于检索到的信息回答用户的问题,并引用相关片段。")
.tools(searchCallback)
.build();
// Agent会自动决定何时调用检索工具
ragAgent.invoke("Spring AI Alibaba支持哪些向量数据库?");
在这个例子中:
- Agent 接收用户问题
- Agent 推理并决定是否需要检索文档
- 如果需要,Agent 调用
search_documents工具 - Agent 使用检索到的信息生成答案
- 如果信息不足,Agent 可以再次调用工具
多工具 Agentic RAG
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import org.springframework.ai.document.Document;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.ai.tool.function.FunctionToolCallback;
import org.springframework.ai.vectorstore.VectorStore;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
// 创建多个检索工具
class WebSearchTool {
public record Request(String query) {}
public record Response(String content) {}
public Response search(Request request) {
return new Response("从网络搜索到的信息: " + request.query());
}
}
class DatabaseQueryTool {
public record Request(String query) {}
public record Response(String content) {}
public Response query(Request request) {
return new Response("从数据库查询到的信息: " + request.query());
}
}
class DocumentSearchTool {
private final VectorStore vectorStore;
public DocumentSearchTool(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public record Request(String query) {}
public record Response(String content) {}
public Response search(Request request) {
List<Document> docs = vectorStore.similaritySearch(request.query());
String content = docs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
return new Response(content);
}
}
WebSearchTool webSearchTool = new WebSearchTool();
DatabaseQueryTool dbQueryTool = new DatabaseQueryTool();
DocumentSearchTool docSearchTool = new DocumentSearchTool(vectorStore);
ToolCallback webSearchCallback = FunctionToolCallback.builder("web_search",
(Function<WebSearchTool.Request, WebSearchTool.Response>)
req -> webSearchTool.search(req))
.description("搜索互联网以获取最新信息")
.inputType(WebSearchTool.Request.class)
.build();
ToolCallback databaseQueryCallback = FunctionToolCallback.builder("database_query",
(Function<DatabaseQueryTool.Request, DatabaseQueryTool.Response>)
req -> dbQueryTool.query(req))
.description("查询内部数据库")
.inputType(DatabaseQueryTool.Request.class)
.build();
ToolCallback documentSearchCallback = FunctionToolCallback.builder("document_search",
(Function<DocumentSearchTool.Request, DocumentSearchTool.Response>)
req -> docSearchTool.search(req))
.description("搜索文档库")
.inputType(DocumentSearchTool.Request.class)
.build();
// Agent可以访问多个检索源
ReactAgent multiSourceAgent = ReactAgent.builder()
.name("multi_source_rag_agent")
.model(chatModel)
.instruction("你可以访问多个信息源:" +
"1. web_search - 用于最新的互联网信息
" +
"2. database_query - 用于内部数据
" +
"3. document_search - 用于文档库
" +
"根据问题选择最合适的工具。")
.tools(webSearchCallback, databaseQueryCallback, documentSearchCallback)
.build();
multiSourceAgent.invoke("比较我们的产品文档中的功能和最新的市场趋势");
混合 RAG
混合 RAG 结合了两步 RAG 和 Agentic RAG 的特点。它引入了中间步骤,如查询预处理、检索验证和生成后检查。这些系统比固定管道提供更多灵活性,同时保持对执行的一定控制。
典型组件包括:
- 查询增强:修改输入问题以提高检索质量。这可能涉及重写不清晰的查询、生成多个变体或用额外上下文扩展查询。
- 检索验证:评估检索到的文档是否相关且充分。如果不够,系统可能会优化查询并再次检索。
- 答案验证:检查生成的答案的准确性、完整性以及与源内容的一致性。如果需要,系统可以重新生成或修订答案。
架构通常支持这些步骤之间的多次迭代:
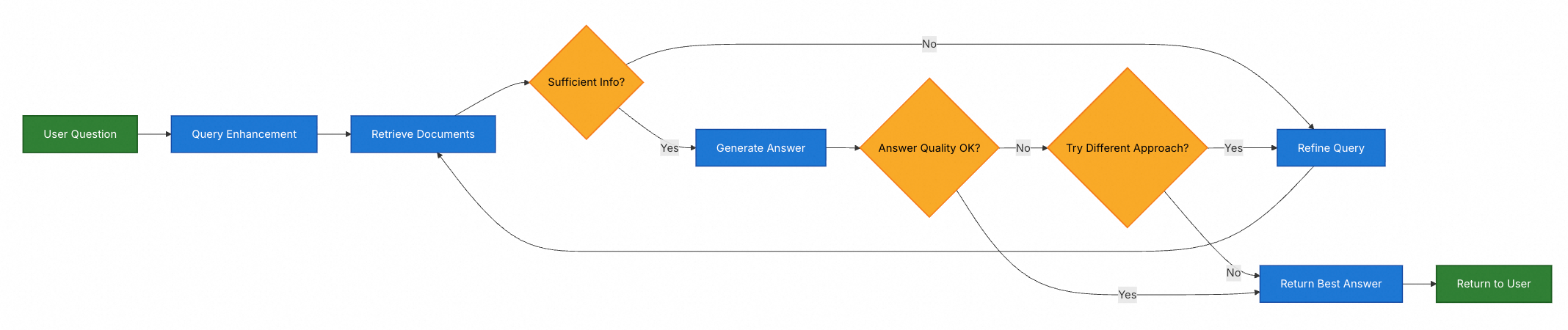
Java 实现示例
混合 RAG 使用 ReactAgent 整合多工具检索和验证步骤:
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
import com.alibaba.cloud.ai.graph.agent.hook.AgentHook;
import com.alibaba.cloud.ai.graph.agent.hook.HookPosition;
import com.alibaba.cloud.ai.graph.agent.hook.HookPositions;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelInterceptor;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelRequest;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelResponse;
import com.alibaba.cloud.ai.graph.agent.interceptor.ModelCallHandler;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.RunnableConfig;
import org.springframework.ai.document.Document;
import org.springframework.ai.tool.ToolCallback;
import org.springframework.ai.tool.function.FunctionToolCallback;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatModel;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
import java.util.function.Function;
import java.util.stream.Collectors;
// 假设你已经有一个配置好的向量存储和 ChatModel
VectorStore vectorStore = ...;
ChatModel chatModel = ...;
// ========== 1. 多工具检索(来自 Agentic RAG) ==========
// 文档搜索工具
class DocumentSearchTool {
private final VectorStore vectorStore;
public DocumentSearchTool(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public record Request(String query) {}
public record Response(String content) {}
public Response search(Request request) {
List<Document> docs = vectorStore.similaritySearch(
org.springframework.ai.vectorstore.SearchRequest.builder()
.query(request.query())
.topK(5)
.build()
);
String content = docs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
return new Response(content);
}
}
// 网络搜索工具(示例)
class WebSearchTool {
public record Request(String query) {}
public record Response(String content) {}
public Response search(Request request) {
// 实际实��现中调用网络搜索 API
return new Response("网络搜索结果: " + request.query());
}
}
DocumentSearchTool docSearchTool = new DocumentSearchTool(vectorStore);
WebSearchTool webSearchTool = new WebSearchTool();
ToolCallback documentSearchCallback = FunctionToolCallback.builder("document_search",
(Function<DocumentSearchTool.Request, DocumentSearchTool.Response>)
req -> docSearchTool.search(req))
.description("从文档库中搜索相关信息")
.inputType(DocumentSearchTool.Request.class)
.build();
ToolCallback webSearchCallback = FunctionToolCallback.builder("web_search",
(Function<WebSearchTool.Request, WebSearchTool.Response>)
req -> webSearchTool.search(req))
.description("从互联网搜索最新信息")
.inputType(WebSearchTool.Request.class)
.build();
// ========== 2. 查询增强 Hook(来自两步 RAG) ==========
@HookPositions({HookPosition.BEFORE_AGENT})
class QueryEnhancementHook extends AgentHook {
private final ChatModel chatModel;
private static final String ENHANCED_QUERY_KEY = "enhanced_query";
public QueryEnhancementHook(ChatModel chatModel) {
this.chatModel = chatModel;
}
@Override
public String getName() {
return "query_enhancement";
}
@Override
public CompletableFuture<Map<String, Object>> beforeAgent(OverAllState state, RunnableConfig config) {
// 从状态中提取用户查询
Optional<Object> messagesOpt = state.value("messages");
if (messagesOpt.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
@SuppressWarnings("unchecked")
List<Message> messages = (List<Message>) messagesOpt.get();
// 提取最后一个用户消息作为查询
String userQuery = messages.stream()
.filter(msg -> msg instanceof UserMessage)
.map(msg -> ((UserMessage) msg).getText())
.reduce((first, second) -> second) // 获取最后一个
.orElse("");
if (userQuery.isEmpty()) {
return CompletableFuture.completedFuture(Map.of());
}
// 使用 LLM 增强查询(只执行一次,在整个 Agent 执行过程中)
// 简化示例:实际可以使用 RewriteQueryTransformer
String enhancedQuery = enhanceQuery(userQuery);
// 如果查询被增强,更新消息列表
if (!enhancedQuery.equals(userQuery)) {
List<Message> enhancedMessages = new ArrayList<>();
// 保留系统消息和其他消息,只替换用户消息
for (Message msg : messages) {
if (msg instanceof UserMessage) {
enhancedMessages.add(new UserMessage(enhancedQuery));
} else {
enhancedMessages.add(msg);
}
}
// 将增强后的查询存储到 metadata 中,供后续使用
config.metadata().ifPresent(meta -> {
meta.put(ENHANCED_QUERY_KEY, enhancedQuery);
});
// 返回更新后的消息列表
return CompletableFuture.completedFuture(Map.of("messages", enhancedMessages));
}
return CompletableFuture.completedFuture(Map.of());
}
private String enhanceQuery(String query) {
// 简化示例:实际可以使用 RewriteQueryTransformer 或调用 LLM 进行查询重写
// 这里只是示例,实际应该调用 LLM 增强查询
// 例如:使用 RewriteQueryTransformer.builder().chatClientBuilder(...).build().transform(query)
return query; // 实际实现中会调用 LLM 增强查询
}
}
// ========== 3. 答案验证 Interceptor(来自两步 RAG) ==========
class AnswerValidationInterceptor extends ModelInterceptor {
private final ChatModel chatModel;
private static final double MIN_CONFIDENCE = 0.7;
public AnswerValidationInterceptor(ChatModel chatModel) {
this.chatModel = chatModel;
}
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 先调用模型生成答案
ModelResponse response = handler.call(request);
// 验证答案质量(简化示例)
AssistantMessage answer = response.getResult().getOutput();
boolean isValid = validateAnswer(answer.getText(), request);
if (!isValid) {
// 如果答案质量不足,可以添加提示要求重新生成
SystemMessage validationPrompt = new SystemMessage(
"请重新检查你的答案,确保基于提供的上下文信息,并且准确完整。"
);
ModelRequest retryRequest = ModelRequest.builder(request)
.systemMessage(validationPrompt)
.build();
// 可以选择重试或返回当前答案
return handler.call(retryRequest);
}
return response;
}
private boolean validateAnswer(String answer, ModelRequest request) {
// 简化示例:实际可以使用 LLM 验证答案与上下文的一致性
// 检查答案长度、是否包含关键信息等
return answer != null && answer.length() > 20; // 简单验证
}
@Override
public String getName() {
return "answer_validation";
}
}
// ========== 4. 创建混合 RAG Agent ==========
ReactAgent hybridRAGAgent = ReactAgent.builder()
.name("hybrid_rag_agent")
.model(chatModel)
.instruction("""
你是一个智能助手,可以访问多个信息源来回答问题。
使用工具时:
1. 优先使用 document_search 搜索文档库
2. 如果需要最新信息,使用 web_search
3. 基于检索到的信息生成准确、完整的答案
4. 如果信息不足,可以多次调用工具
""")
.tools(documentSearchCallback, webSearchCallback)
.hooks(new QueryEnhancementHook(chatModel))
.interceptors(new AnswerValidationInterceptor(chatModel))
.build();
// ========== 5. 使用混合 RAG Agent ==========
AssistantMessage response = hybridRAGAgent.call("Spring AI Alibaba支持哪些向量数据库?");
System.out.println("答案: " + response.getText());
混合 RAG 的特点:
- 多工具检索(Agentic RAG):Agent 可以自主选择使用文档搜索、网络搜索等工具
- 查询增强(两步 RAG):在 Agent 开始时通过
AgentHook增强查询(只执行一次,避免每次 reasoning 循环都调用,降低成本),提高检索质量 - 答案验证(两步 RAG):在生成后通过 Interceptor 验证答案质量,必要时重新生成
- 灵活组合:结合了 Agentic RAG 的灵活性和两步 RAG 的质量控制
性能优化:使用 AgentHook 进行查询增强,只在 Agent 开始时执行一次,而不是每次模型调用前都执行,显著降低了 LLM 调用成本。
这种架构适用于:
- 具有模糊或不明确查询的应用
- 需要验证或质量控制步骤的系统
- 领域特定的问答系统,要求高准确性
最佳实践
-
选择合适的架构:
- 简单 FAQ → 两步 RAG
- 复杂研究任务 → Agentic RAG
- 需要质量保证 → 混合 RAG
-
优化检索质量:
- 使用合适的文本分割策略
- 选择高质量的嵌入模型
- 实现查询重写和扩展
-
控制上下文大小:
- 限制检索到的文档数量
- 使用文档排序和过滤
- 考虑模型的上下文窗口限制
-
监控和评估:
- 跟踪检索质量指标
- 评估答案准确性
- 收集用户反馈
-
性能优化:
- 缓存常见查询的检索结果
- 使用异步检索
- 批量处理文档嵌入
Spring AI Alibaba RAG 组件
Spring AI Alibaba 提供了构建 RAG 系统的核心组件和模块化架构:
// ETL Pipeline 组件
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.DocumentReader; // 文档读取器
import org.springframework.ai.transformer.DocumentTransformer; // 文档转换器(如文本分割)
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore; // 向量存储(DocumentWriter)
// 嵌入模型
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
// 模块化 RAG 组件 - Pre-Retrieval
import org.springframework.ai.rag.query.transformer.QueryTransformer;
import org.springframework.ai.rag.query.transformer.RewriteQueryTransformer;
import org.springframework.ai.rag.query.transformer.CompressionQueryTransformer;
import org.springframework.ai.rag.query.transformer.TranslationQueryTransformer;
import org.springframework.ai.rag.query.expander.QueryExpander;
import org.springframework.ai.rag.query.expander.MultiQueryExpander;
// 模块化 RAG 组件 - Retrieval
import org.springframework.ai.rag.retriever.DocumentRetriever;
import org.springframework.ai.rag.retriever.VectorStoreDocumentRetriever;
import org.springframework.ai.rag.document.join.DocumentJoiner;
import org.springframework.ai.rag.document.join.ConcatenationDocumentJoiner;
// 模块化 RAG 组件 - Post-Retrieval
import org.springframework.ai.rag.postprocessor.DocumentPostProcessor;
// 模块化 RAG 组件 - Generation
import org.springframework.ai.rag.query.augmenter.QueryAugmenter;
import org.springframework.ai.rag.query.augmenter.ContextualQueryAugmenter;
// Advisor API(开箱即用的 RAG 流程)
import org.springframework.ai.chat.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.rag.RetrievalAugmentationAdvisor;
// ChatModel 和 Agent
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.client.ChatClient;
import com.alibaba.cloud.ai.graph.agent.ReactAgent;
// 工具(用于 Agentic RAG)
import org.springframework.ai.tool.ToolCallback;
import org.springframework.ai.tool.function.FunctionToolCallback;
模块化 RAG 架构
Spring AI 实现了模块化 RAG 架构,支持灵活的组件组合:
- Pre-Retrieval(检索前):查询转换(重写、压缩、翻译)、查询扩展(多查询扩展)
- Retrieval(检索):文档搜索、文档连接
- Post-Retrieval(检索后):文档后处理(重排序、去重、压缩)
- Generation(生成):查询增强、上下文注入
这种模块化设计允许你根据需求灵活组合不同的组件,构建适合特定场景的 RAG 流程。详细说明请参考 Retrieval Augmented Generation 模块文档。
相关文档
Agent Framework
- Tools - 创建检索工具
- Agents - 构建 Agentic RAG
- Memory - 对话记忆管理
- Multi-Agent - 多 Agent 协作
RAG 组件
- Retrieval Augmented Generation - RAG API 和模块化架构
- ETL Pipeline - 数据提取、转换和加载
- Document Readers - 文档加载器实现
- Document Parsers - 文档解析器实现
- Embeddings - 嵌入模型 API
- Vector Databases - 向量数据库集成