手把手教你使用 Spring AI 开发 AI 智能体调用 DeepSeek 本地模型


今年的春节注定不寻常,开源大模型领域的“国货之光”们接连发布新版本,多项指标对标 OpenAI 的正式版(收费服务)。
- 1月20日,DeepSeek R1 发布,在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。[1]
- 1月27日,Qwen2.5-1M:支持 100万 Token 上下文,其中 14B 的杯型在短文本任务上实现了和 GPT-4o-mini 相近的性能,同时上下文长度是 GPT-4o-mini 的八倍;长上下文任务在多个数据集上稳定超越 GPT-4o-mini。[2]
- 1月27日,DeepSeek Janus-Pro 发布,多模态理解和生成模型,其中 7B 的杯型在 GenEval 和 DPG-Bench 基准测试中超过 OpenAI 的 DALL-E 3 和 Stable Diffusion。[3]
- 1月28日,Qwen2.5-VL 发布,视觉语言模型,在文档理解、视觉问答、视频理解和视觉 Agent 等维度的多项指标超过 GPT-4o。[4]
- 1月29日,Qwen2.5-Max 发布,在 Arena-Hard、LiveBench、LiveCodeBench 和 GPQA-Diamond 等基准测试中,超越了 DeepSeek V3 和 GPT-4o。[5]
业内开始出现一种声音,开源 LLM 不再仅仅是闭源模型的追随者,而是开始主导 AI 发展的方向,而 DeepSeek 和 Qwen 是目前领跑的开源项目。本文将介绍如何基于开源工具部署大模型、构建测试应用、调用大模型能力的完整链路。
为什么选择 PC 或手机在本地部署?
- 模型计算发生在电脑或手机上,免除算力费用
- API 调用发生在本地网络内,免除 Token 调用费用
- 敏感数据,无需离开本地环境,适合个人开发者体验。
为什么要选择 DeepSeek R1 蒸馏版?
- 由于本地设备的限制,只能运行量化或蒸馏版本。满血版的deepseek-R1, 参数671B,理论上起码需要350G以上显存/内存才能够部署FP4的量化版本。
- DeepSeek R1 开源协议明确可“模型蒸馏”(Distill),且提供了基于 Qwen 的蒸馏版本,可以直接下载使用。
实践
接下来,我们就详细演示如何在本地部署 DeepSeek 模型,并通过 Spring AI Alibaba 开发应用,调用大模型能力。
- 下载 Ollama 并安装运行 DeepSeek 本地模型
- 使用 Spring AI Alibaba 开发应用,调用 DeepSeek 模型
- 无需联网、私有数据完全本地存储,为 Java 应用赋予 AI 智能
本地部署 DeepSeek Qwen 蒸馏版模型
MacOS & Windows 安装
进入 Ollama 官方网站 后,可以看到 Ollama 已经支持 DeepSeek-R1 模型部署:
点击 DeepSeek-R1 的链接可以看到有关 deepseek-r1 的详细介绍:
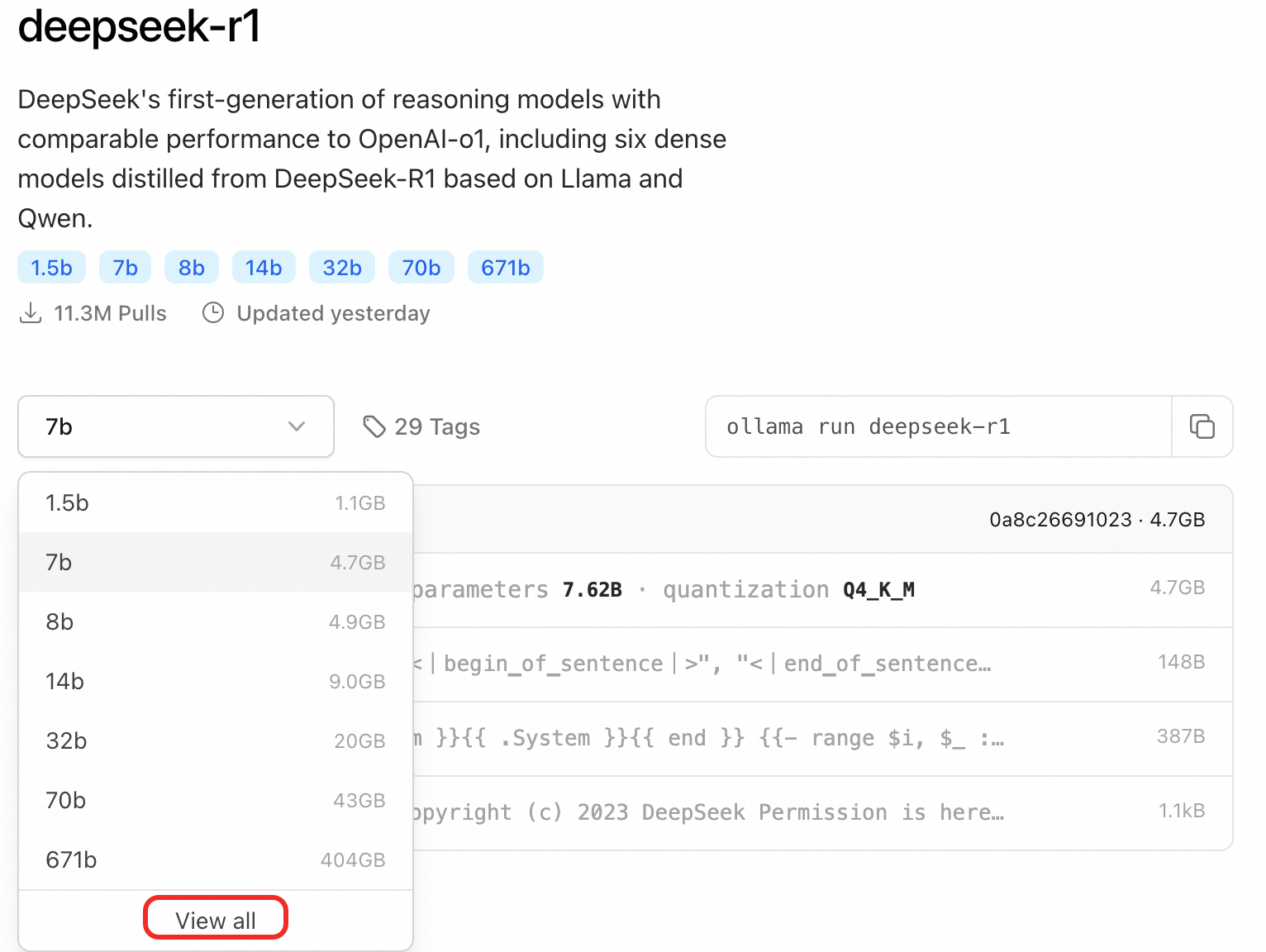
点击 Download 按钮下载并安装 Ollama,安装完成后,按照提示使用 Command + Space 打开终端,运行如下命令:
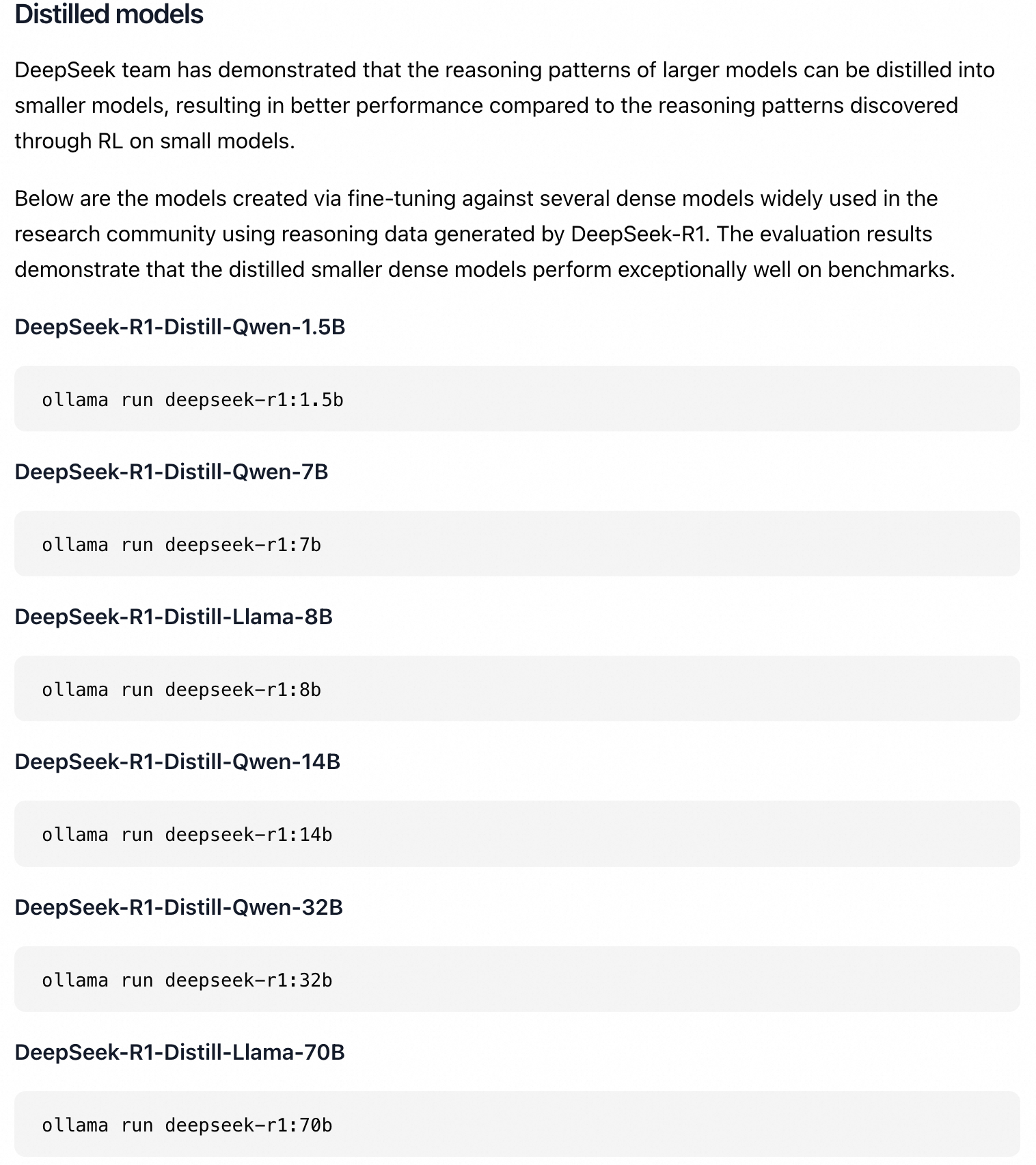
# 运行安装 DeepSeek-R1-Distill-Qwen-1.5B 蒸馏模型
ollama run deepseek-r1:1.5b
Linux 安装
# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 运行安装 DeepSeek-R1-Distill-Qwen-1.5B 蒸馏模型
ollama run deepseek-r1:1.5b
目前 deepseek-r1 模型大小提供了多个选择,包括 1.5b、7b、8b、14b、32b、70b、671b。 请根据你机器的显卡配置进行选择,这里只选择最小的 1.5b 模型来做演示。通常来说,8G 显存可以部署 8B 级别模型;24G 显存可以刚好适配到 32B 的模型。
Spring AI Alibaba 创建应用,调用本地模型
快速运行示例
下载示例源码:
git clone https://github.com/springaialibaba/spring-ai-alibaba-examples.git
cd spring-ai-alibaba-examples/spring-ai-alibaba-chat-example/ollama-deepseek-chat/ollama-deepseek-chat-client
./mvnw compile exec:java -Dexec.mainClass="com.alibaba.cloud.ai.example.chat.deepseek.OllamaChatClientApplication"
打开浏览器,访问 http://localhost:10006/ollama/chat-client/simple/chat,这时应用访问的就是本地部署的 deepseek 模型服务。
源码分析
使用 Spring AI Alibaba 开发应用与使用普通 Spring Boot 没有什么区别,只需要增加 spring-ai-alibaba-starter 依赖,将ChatClient Bean 注入就可以实现与模型聊天了。
在项目中加入 spring-ai-alibaba-starter 依赖,由于咱们的模型是通过 ollama 运行的,这里我们也加入 spring-ai-ollama-spring-boot-starter 依赖。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
<version>1.0.0-M5</version>
</dependency>
配置模型地址,在 application.properties 中配置模型的 baseUrl 与 model 名称。
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.model=deepseek-r1
注入 ChatClient:
@RestController
public class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/chat")
public String chat(String input) {
return this.chatClient.prompt()
.user(input)
.call()
.content();
}
}
总结
以上是本地部署 DeepSeek 本地模型的实践,如果您希望通过云端方式进行部署,可以参考 魔搭+函数计算 FC。
Spring AI Alibaba 钉群群号:105120009405
[1] https://github.com/deepseek-ai/DeepSeek-R1
[2] https://qwenlm.github.io/blog/qwen2.5-vl/
[3] https://github.com/deepseek-ai/Janus?tab=readme-ov-file