

Playground
Spring AI Alibaba Playground is an AI application built by the Spring AI Alibaba community using Spring AI Alibaba and Spring AI frameworks. It includes a comprehensive frontend UI + backend implementation with various AI-related features such as conversation, image generation, tool calling, RAG, MCP, and more. Based on this playground, you can quickly create your own AI application. Features like tool calling, MCP integration, and chat model switching can serve as references for building your own AI applications.
Playground code repository: https://github.com/springaialibaba/spring-ai-alibaba-examples/tree/main/spring-ai-alibaba-playground
Project homepage preview:
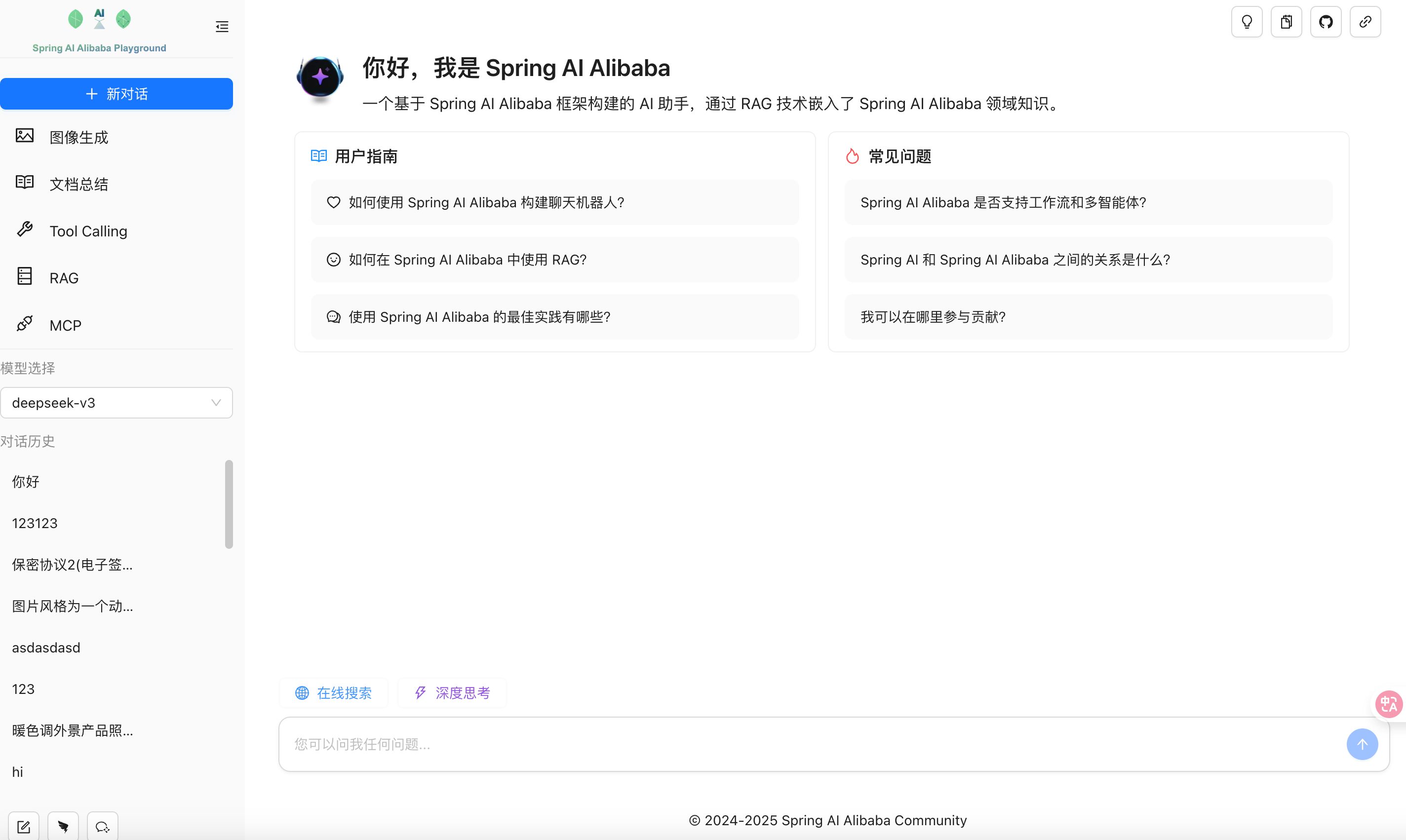
This article contains extensive content covering running the application, project introduction, and configuration details. It is divided into three sections to introduce Spring AI Alibaba Playground. You can navigate to different chapters based on your needs.
Table of Contents
1. Local Running
This section primarily introduces how to start the Playground project locally.
1.1 Download Source Code
Playground code repository: https://github.com/springaialibaba/spring-ai-alibaba-examples/tree/main/spring-ai-alibaba-playground
The playground project is located in the spring-ai-alibaba-example repository, designed as an independent project that doesn’t depend on spring-ai-alibaba-example’s pom management. This means you need to open the playground project directory separately with an IDE rather than starting it directly from the example root directory.
PS: If you start it directly, you need to configure the IDE’s runtime working directory. Please refer to the README description: https://github.com/springaialibaba/spring-ai-alibaba-examples/blob/main/spring-ai-alibaba-playground/README.md
1.2 Configuration Changes
1.2.1 MCP Configuration Changes
Since the playground project incorporates the MCP stdio approach to demonstrate how Spring AI integrates with MCP services, you need to install and configure the environment required to start the MCP Server when your startup environment is Windows.
Taking the following MCP Server JSON configuration file as an example:
{ "mcpServers": { "github": { "command": "npx", "args": [ "/c", "npx", "-y", "@modelcontextprotocol/server-github" ], "env": { "GITHUB_PERSONAL_ACCESS_TOKEN": "your_github_token" } } }}You need to install the NPX tool. If starting on a Windows system, you need to change the command to npx.cmd. Otherwise, startup will fail.
1.2.2 Database File Changes
Playground uses SQLite as the storage database for Chat Memory. When the project starts, it will automatically create a database file named saa.db in the src/main/resources directory. If it’s not created automatically at startup and you encounter startup failures, you need to create this file manually.
1.2.3 Frontend Packaging
The playground frontend project is built by packaging and compiling it into the jar file for joint startup. Therefore, when starting the backend, you need to run mvn clean package. Make sure the frontend project is correctly packaged and compiled; you should see the frontend resource files in the target/classes/static path.
1.2.4 Observability Integration
The Playground project integrates Spring AI’s observability features. You can skip this step if you don’t want to observe metrics during your AI application’s operation.
PS: Since the observability data of AI large model applications contains user input information, please ensure sensitive information options are turned off when deploying to production.
The spring-ai-alibaba-example repository’s docker-compose directory has prepared docker-compose startup files for commonly used AI application tools. You can refer to the startup zipkin.
Observability implementation reference: https://java2ai.com/blog/spring-ai-alibaba-observability-arms/?spm=5176.29160081.0.0.2856aa5cenvkmu
1.2.5 API Key Configuration
The Playground project integrates RAG, vector database, and Function Call features, so you should configure the corresponding API keys at startup.
PS: All keys in the playground are injected via environment variables. If the project still can’t get the API keys after configuring them, please restart your IDE.
- DashScope model API key: For AI application use
- Alibaba Cloud IQS (Information Retrieval Service) API key: For modular RAG examples and web search
- Alibaba Cloud Analytic project database API key: For RAG use
- Baidu Translation and Baidu Map API keys: For Function Call use
- Github personal secret: For MCP Server demonstration
For information on how to obtain these API keys, please search on your own. We won’t go into detail here.
1.3 Start and Access
If all the configuration steps above are complete, after starting the playground project, enter http://localhost:8080 in your browser to see the homepage shown at the beginning of the article.

PS: When experiencing Function Call or MCP functionality, please ensure you’ve configured the corresponding service API keys and that they are valid.
This project is for demonstration purposes only. Some features are just taking shape and are not yet complete. Contributions to the code and improvements to the project are welcome! 🚀
2. Configuration Introduction
As a relatively complete AI application project, the playground project involves multiple configuration files, which will be explained one by one in this section.
2.1 Resources Configuration
The resource directory configuration files are as follows:
resources├── application-dev.yml├── application-prod.yml├── application.yml├── banner.txt├── db├── logback-spring.xml├── mcp-config.yml├── mcp-libs├── models.yaml└── rag- db is the saa.db directory, primarily providing storage support for the playground’s chat memory
- mcp-libs: Directory for MCP Stdio service jars
- rag: Knowledge base document directory for RAG functionality; documents will be automatically vectorized and stored in the vector database at project startup
- mcp-config.yaml: Enhanced mcp-server configuration for the playground project
- application-*.yml: Project startup configuration
2.1.1 MCP Config Enhancement
Problem solved: In the playground, MCP Stdio is used to integrate and demonstrate MCP functionality. When dealing with local services, such as the following configuration:
{ "mcpServers": { "weather": { "command": "java", "args": [ "-Dspring.ai.mcp.server.stdio=true", "-Dspring.main.web-application-type=none", "-Dlogging.pattern.console=", "-jar", "D:\\open_sources\\spring-ai-alibaba-examples\\spring-ai-alibaba-mcp-example\\spring-ai-alibaba-mcp-build-example\\mcp-stdio-server-example\\target\\mcp-stdio-server-example-1.0.0.jar" ], "env": {} } }}When configuring binary files, absolute paths must be used, and the JSON configuration can be difficult to understand. Therefore, the playground enhances the configuration by converting JSON to a semantically clearer YAML definition. For details, please refer to MCP.
2.2 pom.xml Configuration
This section mainly introduces core dependencies. For other dependencies, please refer to: https://github.com/springaialibaba/spring-ai-alibaba-examples/blob/main/spring-ai-alibaba-playground/pom.xml
<dependencies>
<!-- This dependency is required when implementing Chat Memory functionality --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency>
<!-- playground text summarization functionality relies on tika to parse various input texts --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-tika-document-reader</artifactId> <version>${spring-ai.version}</version> </dependency>
<!-- Spring AI MCP client related dependencies--> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-mcp-client</artifactId> <version>${spring-ai.version}</version> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-autoconfigure-mcp-client</artifactId> <version>${spring-ai.version}</version> </dependency>
<!-- Spring AI OpenAI Starter --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-model-openai</artifactId> <version>${spring-ai.version}</version> </dependency>
<!-- Spring AI RAG markdown text reading and parsing --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-markdown-document-reader</artifactId> <version>${spring-ai.version}</version> </dependency>
<!-- Spring AI Vector Database Advisors --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-advisors-vector-store</artifactId> <version>${spring-ai.version}</version> </dependency>
<!-- Spring AI Alibaba DashScope starter --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> <version>${spring-ai-alibaba.version}</version> </dependency>
<!-- Spring AI Alibaba Memory implementation --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-memory</artifactId> <version>${spring-ai-alibaba.version}</version> </dependency>
<!-- Spring AI Alibaba analyticdb vector database integration --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-store-analyticdb</artifactId> <version>${spring-ai-alibaba.version}</version> </dependency>
<!-- DB, providing storage support for ChatMemory and playground --> <dependency> <groupId>org.xerial</groupId> <artifactId>sqlite-jdbc</artifactId> <version>${sqlite-jdbc.version}</version> </dependency>
<dependency> <groupId>org.hibernate.orm</groupId> <artifactId>hibernate-community-dialects</artifactId> <version>${hibernate.version}</version> </dependency>
<!-- Playground observability integration --> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-tracing-bridge-brave</artifactId> <version>${micrometr.version}</version> <exclusions> <exclusion> <artifactId>slf4j-api</artifactId> <groupId>org.slf4j</groupId> </exclusion> </exclusions> </dependency>
</dependencies>
<!-- Spring AI and Spring AI Alibaba dependency management --><dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>${spring-boot.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>${spring-ai-alibaba.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>${spring-ai.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies></dependencyManagement>3. Project Introduction
The playground integrates numerous features, including RAG, MCP, and Function Call. This section will focus on explaining RAG Web Search, MCP calling, and Function Call separately, to help you build an AI application that meets your needs based on this playground.
3.1 RAG Implementation
RAG remains the most popular way to combine AI applications with private knowledge bases. Through RAG, you can build question-answering bots, professional domain assistants, and more.
In the playground project, the vector databases used are analyticdb and the memory-based SimpleVectorStore. You can replace these with any vector database you prefer.
3.1.1 Vector Database Initialization
The initialization configuration code is located at: com/alibaba/cloud/ai/application/config/rag
@BeanCommandLineRunner ingestTermOfServiceToVectorStore(VectorStoreDelegate vectorStoreDelegate) { return args -> { String type = System.getenv("VECTOR_STORE_TYPE"); VectorStoreInitializer initializer = new VectorStoreInitializer(); initializer.init(vectorStoreDelegate.getVectorStore(type)); };}Using VECTOR_STORE_TYPE to choose which type of vector database to use, the VectorStoreDelegate code is as follows. Its purpose is to return a vector database instance bean based on the type value.
PS: Here you can replace it with the vector database you’re using to build RAG functionality.
public class VectorStoreDelegate {
private VectorStore simpleVectorStore;
private VectorStore analyticdbVectorStore;
public VectorStoreDelegate(VectorStore simpleVectorStore, VectorStore analyticdbVectorStore) { this.simpleVectorStore = simpleVectorStore; this.analyticdbVectorStore = analyticdbVectorStore; }
public VectorStore getVectorStore(String vectorStoreType) {
if (Objects.equals(vectorStoreType, "analyticdb") && analyticdbVectorStore != null) { return analyticdbVectorStore; }
return simpleVectorStore; }}3.1.2 RAG Document Initialization
In VectorStoreInitializer, the MD documents under resources/rag are vectorized and loaded into the vector database:
public void init(VectorStore vectorStore) throws Exception { List<MarkdownDocumentReader> markdownDocumentReaderList = loadMarkdownDocuments();
int size = 0; if (markdownDocumentReaderList.isEmpty()) { logger.warn("No markdown documents found in the directory."); return; }
logger.debug("Start to load markdown documents into vector store......"); for (MarkdownDocumentReader markdownDocumentReader : markdownDocumentReaderList) { List<Document> documents = new TokenTextSplitter(2000, 1024, 10, 10000, true).transform(markdownDocumentReader.get()); size += documents.size();
// Split documents list into sublists with a maximum of 25 elements for (int i = 0; i < documents.size(); i += 25) { int end = Math.min(i + 25, documents.size()); List<Document> subList = documents.subList(i, end); vectorStore.add(subList); } } logger.debug("Load markdown documents into vector store successfully. Load {} documents.", size);}3.1.3 Building the Service
In the business code, inject the vector database bean to complete the implementation of RAG functionality:
@Servicepublic class SAARAGService {
private final ChatClient client;
private final VectorStoreDelegate vectorStoreDelegate;
private String vectorStoreType;
public SAARAGService( VectorStoreDelegate vectorStoreDelegate, SimpleLoggerAdvisor simpleLoggerAdvisor, MessageChatMemoryAdvisor messageChatMemoryAdvisor, @Qualifier("dashscopeChatModel") ChatModel chatModel, @Qualifier("systemPromptTemplate") PromptTemplate systemPromptTemplate ) { this.vectorStoreType = System.getenv("VECTOR_STORE_TYPE"); this.vectorStoreDelegate = vectorStoreDelegate; this.client = ChatClient.builder(chatModel) .defaultSystem( systemPromptTemplate.getTemplate() ).defaultAdvisors( messageChatMemoryAdvisor, simpleLoggerAdvisor ).build(); }
public Flux<String> ragChat(String chatId, String prompt) {
return client.prompt() .user(prompt) .advisors(memoryAdvisor -> memoryAdvisor .param(ChatMemory.CONVERSATION_ID, chatId) ).advisors( QuestionAnswerAdvisor .builder(vectorStoreDelegate.getVectorStore(vectorStoreType)) .searchRequest( SearchRequest.builder() // TODO all documents retrieved from ADB are under 0.1// .similarityThreshold(0.6d) .topK(6) .build() ) .build() ).stream() .content(); }
}RAG implementation reference article: https://java2ai.com/blog/spring-ai-alibaba-rag-ollama/?spm=5176.29160081.0.0.2856aa5cenvkmu
3.2 Web Search Feature Implementation
In the Qwen model, you can enable the model’s web search capability through enable_search. In playground, web search functionality is integrated through the Module RAG approach.
3.2.1 Module RAG Introduction
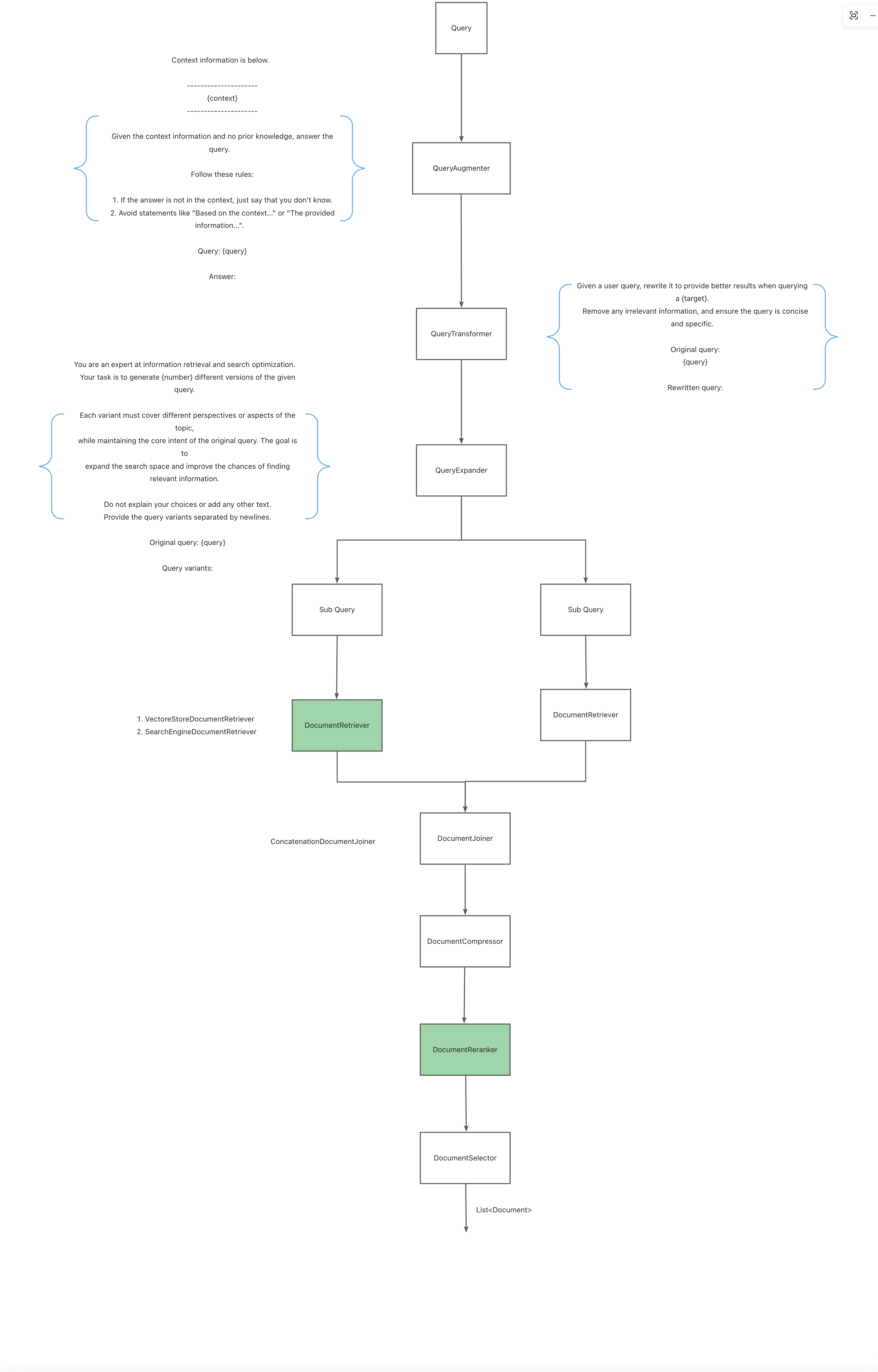
Spring AI implements a modular RAG architecture, inspired by the modular concept detailed in the paper “Modular RAG: Transforming RAG Systems into a Lego-like Reconfigurable Framework”. RAG is divided into three steps:
Pre-Retrieval
Enhance and transform user input to make it more effective for retrieval tasks, addressing improperly formatted queries, semantically unclear queries, or unsupported languages.
- QueryAugmenter: Enhances user queries with additional contextual data, providing necessary context information for the model to answer questions
- QueryTransformer: Since user input is often one-sided with limited key information, making it difficult for the model to understand and answer questions, query rewriting is needed using prompt tuning or model-based query rewriting
- QueryExpander: Expands user queries into multiple semantically different variants to gain different perspectives, helping to retrieve additional contextual information and increasing the chances of finding relevant results
Retrieval
Responsible for querying vector stores and other data systems to retrieve documents most relevant to the user query.
- DocumentRetriever: Retrieves from different data sources based on the QueryExpander, such as search engines, vector stores, databases, or knowledge graphs
- DocumentJoiner: Merges documents retrieved from multiple queries and multiple data sources into a single document collection
Post-Retrieval
Responsible for processing retrieved documents to obtain the best output results, solving issues like “middle loss” in the model and context length limitations.
PS: Spring AI deprecated DocumentRanker in version 1.0.0. You can implement the DocumentPostProcessor interface to achieve this functionality. To be added to Playground.
Generation
Generates model output corresponding to the user’s query.
3.2.2 Data Source
Web search, as the name implies, retrieves data from the internet through real-time searches and feeds it to the large model to obtain the latest information and news. The playground project uses Alibaba Cloud’s IQS (Information Retrieval Service) as the data source for web search. You can replace IQS with a search engine service.
The IQS search implementation is as follows, essentially requesting a service interface or calling an SDK:
public GenericSearchResult search(String query) {
// String encodeQ = URLEncoder.encode(query, StandardCharsets.UTF_8); ResponseEntity<GenericSearchResult> resultResponseEntity = run(query);
return genericSearchResult(resultResponseEntity);}
private ResponseEntity<GenericSearchResult> run(String query) {
return this.restClient.get() .uri( "/search/genericSearch?query={query}&timeRange={timeRange}", query, TIME_RANGE ).retrieve() .toEntity(GenericSearchResult.class);}
}3.2.3 Data Processing
In this step, the data obtained from the search engine is cleaned and converted into Spring AI Document format:
public List<Document> getData(GenericSearchResult respData) throws URISyntaxException {
List<Document> documents = new ArrayList<>();
Map<String, Object> metadata = getQueryMetadata(respData);
for (ScorePageItem pageItem : respData.getPageItems()) {
Map<String, Object> pageItemMetadata = getPageItemMetadata(pageItem); Double score = getScore(pageItem); String text = getText(pageItem);
if (Objects.equals("", text)) {
Media media = getMedia(pageItem); Document document = new Document.Builder() .metadata(metadata) .metadata(pageItemMetadata) .media(media) .score(score) .build();
documents.add(document); break; }
Document document = new Document.Builder() .metadata(metadata) .metadata(pageItemMetadata) .text(text) .score(score) .build();
documents.add(document); }
return documents; }
private Double getScore(ScorePageItem pageItem) {
return pageItem.getScore(); }
// .... omitted data cleaning code
// Limit the number of documents for web search to improve response speed public List<Document> limitResults(List<Document> documents, int minResults) {
int limit = Math.min(documents.size(), minResults);
return documents.subList(0, limit); }
}3.2.4 Module RAG Process
Next is using the Module RAG API to process user prompts, making them more suitable for model input/output to achieve better results.
For specific code, refer to: https://github.com/springaialibaba/spring-ai-alibaba-examples/tree/main/spring-ai-alibaba-playground/src/main/java/com/alibaba/cloud/ai/application/rag
3.2.5 Web Search Service Class
- Inject related beans in the constructor
- Implement modular RAG web search functionality through RetrievalAugmentationAdvisor in ChatClient
public SAAWebSearchService( DataClean dataCleaner, QueryExpander queryExpander, IQSSearchEngine searchEngine, QueryTransformer queryTransformer, SimpleLoggerAdvisor simpleLoggerAdvisor, @Qualifier("dashscopeChatModel") ChatModel chatModel, @Qualifier("queryArgumentPromptTemplate") PromptTemplate queryArgumentPromptTemplate) {
this.queryTransformer = queryTransformer; this.queryExpander = queryExpander; this.queryArgumentPromptTemplate = queryArgumentPromptTemplate;
// reasoning content for DeepSeek-r1 is integrated into the output this.reasoningContentAdvisor = new ReasoningContentAdvisor(1);
// Build chatClient this.chatClient = ChatClient.builder(chatModel) .defaultOptions( DashScopeChatOptions.builder() .withModel(DEFAULT_WEB_SEARCH_MODEL) // whether to enable incremental output in stream mode .withIncrementalOutput(true) .build()) .build();
// logging this.simpleLoggerAdvisor = simpleLoggerAdvisor;
this.webSearchRetriever = WebSearchRetriever.builder() .searchEngine(searchEngine) .dataCleaner(dataCleaner) .maxResults(2) .build();}
//Handle user inputpublic Flux<String> chat(String prompt) {
return chatClient.prompt() .advisors( createRetrievalAugmentationAdvisor(), reasoningContentAdvisor, simpleLoggerAdvisor ).user(prompt) .stream() .content();}
private RetrievalAugmentationAdvisor createRetrievalAugmentationAdvisor() {
return RetrievalAugmentationAdvisor.builder() .documentRetriever(webSearchRetriever) .queryTransformers(queryTransformer) .queryAugmenter( new CustomContextQueryAugmenter( queryArgumentPromptTemplate, null, true) ).queryExpander(queryExpander) .documentJoiner(new ConcatenationDocumentJoiner()) .build();}Web Search implementation reference article: https://java2ai.com/blog/spring-ai-alibaba-module-rag/?spm=5176.29160081.0.0.2856aa5cenvkmu&source=blog/
Spring AI RAG: https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.html#_advisors
3.3 MCP Integration
3.3.1 MCP Config Enhancement
To address the difficulty in understanding MCP Stdio JSON configuration files and the absolute path requirement for local MCP Server binary files, the playground enhances the MCP Stdio configuration.
The main step is to rewrite the McpStdioClientProperties attribute configuration for subsequent use in MCP Client initialization with enhanced MCP configuration:
@Componentpublic class CustomMcpStdioTransportConfigurationBeanPostProcessor implements BeanPostProcessor {
private static final Logger logger = LoggerFactory.getLogger(CustomMcpStdioTransportConfigurationBeanPostProcessor.class);
private final ObjectMapper objectMapper;
private final McpStdioClientProperties mcpStdioClientProperties;
public CustomMcpStdioTransportConfigurationBeanPostProcessor( ObjectMapper objectMapper, McpStdioClientProperties mcpStdioClientProperties ) { this.objectMapper = objectMapper; this.mcpStdioClientProperties = mcpStdioClientProperties; }
@NotNull @Override public Object postProcessAfterInitialization(@NotNull Object bean, @NotNull String beanName) throws BeansException {
if (bean instanceof StdioTransportAutoConfiguration) {
logger.debug("Enhancing McpStdioTransportConfiguration bean start: {}", beanName);
McpServerConfig mcpServerConfig; try { mcpServerConfig = McpServerUtils.getMcpServerConfig();
// Handle the jar relative path issue in the configuration file. for (Map.Entry<String, McpStdioClientProperties.Parameters> entry : mcpServerConfig.getMcpServers() .entrySet()) {
if (entry.getValue() != null && entry.getValue().command().startsWith("java")) {
McpStdioClientProperties.Parameters serverConfig = entry.getValue(); String oldMcpLibsPath = McpServerUtils.getLibsPath(serverConfig.args()); String rewriteMcpLibsAbsPath = getMcpLibsAbsPath(McpServerUtils.getLibsPath(serverConfig.args())); if (rewriteMcpLibsAbsPath != null) { serverConfig.args().remove(oldMcpLibsPath); serverConfig.args().add(rewriteMcpLibsAbsPath); } } }
String msc = objectMapper.writeValueAsString(mcpServerConfig); logger.debug("Registry McpServer config: {}", msc);
// write mcp client mcpStdioClientProperties.setServersConfiguration(new ByteArrayResource(msc.getBytes())); ((StdioTransportAutoConfiguration) bean).stdioTransports(this.mcpStdioClientProperties); } catch (IOException e) { throw new SAAAppException(e.getMessage()); }
logger.debug("Enhancing McpStdioTransportConfiguration bean end: {}", beanName); }
return bean; }
}In MCPServerUtils, the mcp-config.yaml configuration is read and converted to McpServerConfig:
public static McpServerConfig getMcpServerConfig() throws IOException {
ObjectMapper mapper = new ObjectMapper(new YAMLFactory()); InputStream resourceAsStream = ModelsUtils.class.getClassLoader().getResourceAsStream(MCP_CONFIG_FILE_PATH);
McpServerConfig mcpServerConfig = mapper.readValue(resourceAsStream, McpServerConfig.class); mcpServerConfig.getMcpServers().forEach((key, parameters) -> { Map<String, String> env = parameters.env(); if (Objects.nonNull(env)) { env.entrySet().stream() .filter(entry -> entry.getValue() != null && !entry.getValue().isEmpty() && entry.getValue().startsWith("${") && entry.getValue().endsWith("}")) .forEach(entry -> { String envKey = entry.getValue().substring(2, entry.getValue().length() - 1); String envValue = System.getenv(envKey); // allow env is null. if (envValue != null && !envValue.isEmpty()) { env.put(entry.getKey(), envValue); } }); } });
return mcpServerConfig;}3.3.2 MCP Server Tool Display
To facilitate displaying how MCP Client calls MCP Server tools and what tools are available in MCP Server, the playground has implemented special handling.
Custom MCP Server stores MCP Server tool information for browser display:
public class McpServer {
private String id;
private String name;
private String desc;
private Map<String, String> env;
private List<Tools> toolList;}Since Spring AI’s SyncMcpToolCallback doesn’t expose properties for getting MCP Server related attributes (only Tool definitions), playground wraps SyncMcpToolCallback:
public class SyncMcpToolCallbackWrapper {
private final SyncMcpToolCallback callback;
public SyncMcpToolCallbackWrapper(SyncMcpToolCallback callback) { this.callback = callback; }
public McpSyncClient getMcpClient() {
try { Field field = SyncMcpToolCallback.class.getDeclaredField("mcpClient"); field.setAccessible(true); return (McpSyncClient) field.get(callback); } catch (NoSuchFieldException | IllegalAccessException e) { throw new RuntimeException(e); } }
}MCPServerUtils initializes the MCP Server container:
public static void initMcpServerContainer(ToolCallbackProvider toolCallbackProvider) throws IOException {
McpServerConfig mcpServerConfig = McpServerUtils.getMcpServerConfig(); Map<String, String> mcpServerDescMap = initMcpServerDescMap();
mcpServerConfig.getMcpServers().forEach((key, parameters) -> {
List<McpServer.Tools> toolsList = new ArrayList<>(); for (ToolCallback toolCallback : toolCallbackProvider.getToolCallbacks()) {
// todo: can't get mcp client, use wrapper for now SyncMcpToolCallback mcpToolCallback = (SyncMcpToolCallback) toolCallback; SyncMcpToolCallbackWrapper syncMcpToolCallbackWrapper = new SyncMcpToolCallbackWrapper(mcpToolCallback); String currentMcpServerName = syncMcpToolCallbackWrapper.getMcpClient().getServerInfo().name();
// aggregate mcp server tools by mcp server name if (Objects.equals(key, currentMcpServerName)) { McpServer.Tools tool = new McpServer.Tools(); tool.setDesc(toolCallback.getToolDefinition().description()); tool.setName(toolCallback.getToolDefinition().name()); tool.setParams(toolCallback.getToolDefinition().inputSchema());
toolsList.add(tool); } }
McpServerContainer.addServer(McpServer.builder() .id(getId()) .name(key) .env(parameters.env()) .desc(mcpServerDescMap.get(key)) .toolList(toolsList) .build() ); });
}MCP Server tool display effect is shown below. You can add more MCP Servers in the mcp-config.yaml file under resources:

3.3.3 MCP Tool Calling
After completing the initialization operations above, the next step is to write the MCP Service class. To be able to get information about MCP Server Tools execution, Spring AI Tools’ internalToolExecutionEnabled API is used here to collect tool input parameters and execution results from the model for display in the frontend.
To collect information during MCP Tools calling, the Playground project wrote a ToolCallResp class:
public class ToolCallResp {
/** * Tool execution status */ private ToolState status;
/** * Tool Name */ private String toolName;
/** * Tool execution parameters */ private String toolParameters;
/** * Tool execution result */ private String toolResult;
/** * Tool execution start timestamp */ private LocalDateTime toolStartTime;
/** * Tool execution end timestamp */ private LocalDateTime toolEndTime;
/** * Tool execution error message */ private String errorMessage;
/** * Tool execution input */ private String toolInput;
/** * Tool execution time cost */ private Long toolCostTime; /** * Tool intermediate result returned by the tool */ private String toolResponse;}MCP Service implementation:
@Servicepublic class SAAMcpService {
private final ChatClient chatClient;
private final ObjectMapper objectMapper;
private final ToolCallbackProvider tools;
private final ToolCallingManager toolCallingManager;
private final McpStdioClientProperties mcpStdioClientProperties;
private static final Logger logger = LoggerFactory.getLogger(SAAMcpService.class);
public SAAMcpService( ObjectMapper objectMapper, ToolCallbackProvider tools, SimpleLoggerAdvisor simpleLoggerAdvisor, ToolCallingManager toolCallingManager, McpStdioClientProperties mcpStdioClientProperties, @Qualifier("openAiChatModel") ChatModel chatModel ) throws IOException {
this.objectMapper = objectMapper; this.mcpStdioClientProperties = mcpStdioClientProperties;
// Initialize chat client with non-blocking configuration this.chatClient = ChatClient.builder(chatModel) .defaultAdvisors( simpleLoggerAdvisor ).defaultToolCallbacks(tools) .build(); this.tools = tools; this.toolCallingManager = toolCallingManager;
McpServerUtils.initMcpServerContainer(tools); }
public ToolCallResp chat(String prompt) {
// manual run tools flag ChatOptions chatOptions = ToolCallingChatOptions.builder() .toolCallbacks(tools.getToolCallbacks()) .internalToolExecutionEnabled(false) .build();
ChatResponse response = chatClient.prompt(new Prompt(prompt, chatOptions)) .call().chatResponse();
logger.debug("ChatResponse: {}", response); assert response != null; List<AssistantMessage.ToolCall> toolCalls = response.getResult().getOutput().getToolCalls(); logger.debug("ToolCalls: {}", toolCalls); String responseByLLm = response.getResult().getOutput().getText(); logger.debug("Response by LLM: {}", responseByLLm);
// execute tools with no chat memory messages. var tcr = ToolCallResp.TCR(); if (!toolCalls.isEmpty()) {
tcr = ToolCallResp.startExecute( responseByLLm, toolCalls.get(0).name(), toolCalls.get(0).arguments() ); tcr.setToolParameters(toolCalls.get(0).arguments()); logger.debug("Start ToolCallResp: {}", tcr); ToolExecutionResult toolExecutionResult = null;
try { toolExecutionResult = toolCallingManager.executeToolCalls(new Prompt(prompt, chatOptions), response);
tcr.setToolEndTime(LocalDateTime.now()); } catch (Exception e) {
tcr.setStatus(ToolCallResp.ToolState.FAILURE); tcr.setErrorMessage(e.getMessage()); tcr.setToolEndTime(LocalDateTime.now()); tcr.setToolCostTime((long) (tcr.getToolEndTime().getNano() - tcr.getToolStartTime().getNano())); logger.error("Error ToolCallResp: {}, msg: {}", tcr, e.getMessage()); // throw new RuntimeException("Tool execution failed, please check the logs for details."); }
String llmCallResponse = ""; if (Objects.nonNull(toolExecutionResult)) { ChatResponse finalResponse = chatClient.prompt().messages(toolExecutionResult.conversationHistory()) .call().chatResponse(); if (finalResponse != null) { llmCallResponse = finalResponse.getResult().getOutput().getText(); }
StringBuilder sb = new StringBuilder(); toolExecutionResult.conversationHistory().stream() .filter(message -> message instanceof ToolResponseMessage) .forEach(message -> { ToolResponseMessage toolResponseMessage = (ToolResponseMessage) message; toolResponseMessage.getResponses().forEach(tooResponse -> { sb.append(tooResponse.responseData()); }); }); tcr.setToolResponse(sb.toString()); }
tcr.setStatus(ToolCallResp.ToolState.SUCCESS); tcr.setToolResult(llmCallResponse); tcr.setToolCostTime((long) (tcr.getToolEndTime().getNano() - tcr.getToolStartTime().getNano())); logger.debug("End ToolCallResp: {}", tcr); } else { logger.debug("ToolCalls is empty, no tool execution needed."); tcr.setToolResult(responseByLLm); }
return tcr; }
public ToolCallResp run(String id, Map<String, String> envs, String prompt) throws IOException {
Optional<McpServer> runMcpServer = McpServerContainer.getServerById(id); if (runMcpServer.isEmpty()) { logger.error("McpServer not found, id: {}", id); return ToolCallResp.TCR(); }
String runMcpServerName = runMcpServer.get().getName(); var mcpServerConfig = McpServerUtils.getMcpServerConfig(); McpStdioClientProperties.Parameters parameters = new McpStdioClientProperties.Parameters( mcpServerConfig.getMcpServers().get(runMcpServerName).command(), mcpServerConfig.getMcpServers().get(runMcpServerName).args(), envs );
if (parameters.command().startsWith("java")) { String oldMcpLibsPath = McpServerUtils.getLibsPath(parameters.args()); String rewriteMcpLibsAbsPath = getMcpLibsAbsPath(McpServerUtils.getLibsPath(parameters.args()));
parameters.args().remove(oldMcpLibsPath); parameters.args().add(rewriteMcpLibsAbsPath); }
String mcpServerConfigJSON = objectMapper.writeValueAsString(mcpServerConfig); mcpStdioClientProperties.setServersConfiguration(new ByteArrayResource(mcpServerConfigJSON.getBytes()));
return chat(prompt); }
}Function Call reference: https://docs.spring.io/spring-ai/reference/api/tools.html
MCP Server article reference: https://java2ai.com/blog/spring-ai-alibaba-mcp/?spm=5176.29160081.0.0.2856aa5cenvkmu
3.4 Function Call Integration
The playground implements Function Call functionality, supporting call status display similar to MCP. The tool browser display works on the same principle.
3.4.1 Function Tools Initialization
You can use Spring AI Alibaba’s Tool Calling Starter to introduce tools, or like Playground, customize tools through FunctionToolCallback.
Playground Tools: https://github.com/springaialibaba/spring-ai-alibaba-examples/tree/main/spring-ai-alibaba-playground/src/main/java/com/alibaba/cloud/ai/application/tools
Tools initialization code:
public List<ToolCallback> getTools() {
return List.of(buildBaiduTranslateTools(), buildBaiduMapTools());}
private ToolCallback buildBaiduTranslateTools() {
return FunctionToolCallback .builder( "BaiduTranslateService", new BaiduTranslateTools(ak, sk, restClientbuilder, responseErrorHandler) ).description("Baidu translation function for general text translation.") .inputSchema( """ { "type": "object", "properties": { "Request": { "type": "object", "properties": { "q": { "type": "string", "description": "Content that needs to be translated." }, "from": { "type": "string", "description": "Source language that needs to be translated." }, "to": { "type": "string", "description": "Target language to translate into." } }, "required": ["q", "from", "to"], "description": "Request object to translate text to a target language." }, "Response": { "type": "object", "properties": { "translatedText": { "type": "string", "description": "The translated text." } }, "required": ["translatedText"], "description": "Response object for the translation function, containing the translated text." } }, "required": ["Request", "Response"] } """ ).inputType(BaiduTranslateTools.BaiduTranslateToolRequest.class) .toolMetadata(ToolMetadata.builder().returnDirect(false).build()) .build();}3.4.2 Function Tools Calling
After introducing or defining the tools, you can use these tools in the service to enhance the capabilities of the large model. The tool calling code is similar to MCP Server Tools:
public class SAAToolsService {
private static final Logger logger = LoggerFactory.getLogger(SAAToolsService.class);
private final ChatClient chatClient;
private final ToolCallingManager toolCallingManager;
private final ToolsInit toolsInit;
public SAAToolsService( ToolsInit toolsInit, ToolCallingManager toolCallingManager, SimpleLoggerAdvisor simpleLoggerAdvisor, MessageChatMemoryAdvisor messageChatMemoryAdvisor, @Qualifier("openAiChatModel") ChatModel chatModel ) {
this.toolsInit = toolsInit; this.toolCallingManager = toolCallingManager;
this.chatClient = ChatClient.builder(chatModel) .defaultAdvisors( simpleLoggerAdvisor// messageChatMemoryAdvisor ).build(); }
public ToolCallResp chat(String prompt) {
// manual run tools flag ChatOptions chatOptions = ToolCallingChatOptions.builder() .toolCallbacks(toolsInit.getTools()) .internalToolExecutionEnabled(false) .build(); Prompt userPrompt = new Prompt(prompt, chatOptions);
ChatResponse response = chatClient.prompt(userPrompt) .call().chatResponse();
logger.debug("ChatResponse: {}", response); assert response != null; List<AssistantMessage.ToolCall> toolCalls = response.getResult().getOutput().getToolCalls(); logger.debug("ToolCalls: {}", toolCalls); String responseByLLm = response.getResult().getOutput().getText(); logger.debug("Response by LLM: {}", responseByLLm);
// execute tools with no chat memory messages. var tcr = ToolCallResp.TCR(); if (!toolCalls.isEmpty()) {
tcr = ToolCallResp.startExecute( responseByLLm, toolCalls.get(0).name(), toolCalls.get(0).arguments() ); logger.debug("Start ToolCallResp: {}", tcr); ToolExecutionResult toolExecutionResult = null;
try { toolExecutionResult = toolCallingManager.executeToolCalls(new Prompt(prompt, chatOptions), response);
tcr.setToolEndTime(LocalDateTime.now()); } catch (Exception e) {
tcr.setStatus(ToolCallResp.ToolState.FAILURE); tcr.setErrorMessage(e.getMessage()); tcr.setToolEndTime(LocalDateTime.now()); tcr.setToolCostTime((long) (tcr.getToolEndTime().getNano() - tcr.getToolStartTime().getNano())); logger.error("Error ToolCallResp: {}, msg: {}", tcr, e.getMessage()); // throw new RuntimeException("Tool execution failed, please check the logs for details."); }
String llmCallResponse = ""; if (Objects.nonNull(toolExecutionResult)) {// ToolResponseMessage toolResponseMessage = (ToolResponseMessage) toolExecutionResult.conversationHistory()// .get(toolExecutionResult.conversationHistory().size() - 1);// llmCallResponse = toolResponseMessage.getResponses().get(0).responseData(); ChatResponse finalResponse = chatClient.prompt().messages(toolExecutionResult.conversationHistory()).call().chatResponse(); llmCallResponse = finalResponse.getResult().getOutput().getText(); }
tcr.setStatus(ToolCallResp.ToolState.SUCCESS); tcr.setToolResult(llmCallResponse); tcr.setToolCostTime((long) (tcr.getToolEndTime().getNano() - tcr.getToolStartTime().getNano())); logger.debug("End ToolCallResp: {}", tcr); } else { logger.debug("ToolCalls is empty, no tool execution needed."); tcr.setToolResult(responseByLLm); }
return tcr; }
}Function Tools integration article reference: https://java2ai.com/blog/spring-ai-toolcalling/?spm=5176.29160081.0.0.2856aa5cenvkmu
3.5 Frontend Page
The Playground frontend is implemented using React and provides a basic frontend interface for the above features. You can refer to the following key information to make some custom modifications.
3.5.1 Data Persistence
Some business scenarios require data persistence to query historical records. In production environments, it is recommended to use server-side storage for records, but for demonstration purposes, the Playground currently saves all historical data to the client’s local storage by default. The implementation can be referenced from the following code:
/** * Handle the complete message sending process * @param text - Message text * @param sendRequest - Function to send the request * @param createMessage - Function to create the message object */const processSendMessage = async <T extends BaseMessage>({ text, sendRequest, createMessage,}: { text: string; sendRequest: (text: string, timestamp: number, message: T) => Promise<void>; createMessage: (text: string, timestamp: number) => T;}) => { if (!text.trim() || !activeConversation) return;
const userTimestamp = Date.now(); const userMessage = createMessage(text, userTimestamp);
// Store user data locally on the client. In production environments, this step can be omitted and handled by the server updateActiveConversation({ ...activeConversation, messages: [ ...activeConversation.messages, userMessage, ] as T[], });
try { await sendRequest(text, userTimestamp, userMessage); } catch (error) { console.error("error:", error); }};3.5.2 Custom Message Text Style Rendering
The conversation bubble component supports rich text style rendering and has good extensibility. You can refer to the following code to extend custom styles for any tag:
/** * Get custom rendering configuration * @param style - css styles */const getMarkdownRenderConfig = (styles: Record<string, string>) => {
return { div: ({ children }) => { return <pre className={styles.codeBlock}>{children}</pre> }, code: ({ children, className }) => { return <code className={styles.codeInline}>{children}</code> }, think: ({ children }) => { return <div className={styles.thinkTag}>{children}</div>; }, tool: ({ children }) => { return <div className={styles.toolTag}>{children}</div>; }, };};You can also use regex matching and other methods for syntax analysis to modify strings in specific formats to be wrapped in custom tags, and then set their rendering styles using the method above, implementing complex styles such as interactive forms, charts, etc.
4. Summary
The Spring AI Alibaba official community has developed a complete AI agent Playground example with both frontend UI + backend implementation. The community will continue to update and maintain it in the future to demonstrate the latest features of Spring AI and Spring AI Alibaba.