提示词工程模式
基于全面的提示工程指南,我们将对即时工程技术进行实际应用。该指南涵盖了有效即时工程的理论、原则和模式, 并演示了如何使用 Spring AI ChatClient Fluent API 将这些概念转化为可运行的 Java 代码。
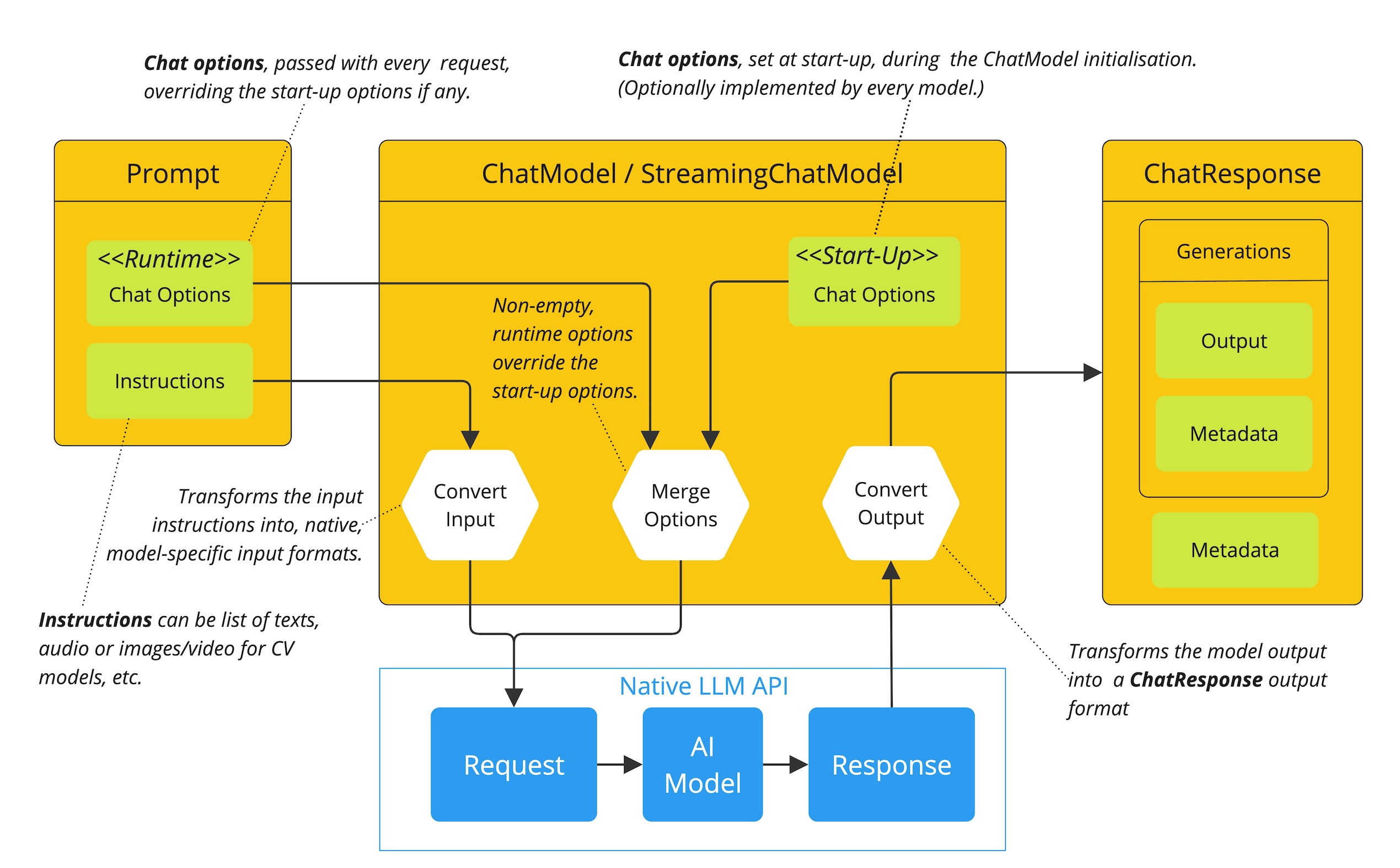
1,配置
配置部分概述了如何使用 Spring AI 设置和调整大型语言模型 (LLM)。它涵盖了如何根据用例选择合适的 LLM 提供程序,以及如何配置重要的生成参数,以控制模型输出的质量、样式和格式。
模型选择
为了快速进行工程设计,您需要先选择一个模型。Spring AI 支持多个 LLM 模型,让您无需更改应用程序代码即可切换模型 - 只需更新配置即可。只需添加所�选的启动依赖项即可spring-ai-starter-model-<MODEL-PROVIDER-NAME>。例如,以下是如何启用 Anthropic Claude API:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-anthropic</artifactId>
</dependency>
您可以像这样指定 LLM 模型名称:
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest") // 使用 Anthropic 的 Claude 模型
.build())
模型输出配置
在深入研究即时工程技术之前,我们有必要了解如何配置 LLM 的输出行为。Spring AI 提供了多个配置选项,可让您通过 ChatOptions 构建器控制生成的各个方面。
所有配置都可以以编程方式应用,如下面的示例所示,或者在启动时通过 Spring 应用程序属性应用。
Temperature
Temperature 控制模型响应的随机性或“创造性”。
较低值(0.0-0.3):响应更确定、更集中。更适合事实类问题、分类问题或一致性至关重要的任务。
中等值(0.4-0.7):在确定性和创造性之间取得平衡。适用于一般用例。
值越高 (0.8-1.0):回复更具创意、多样性,且可能带来惊喜。更适合创意写作、头脑风暴或生成多样化选项。
.options(ChatOptions.builder()
.temperature(0.1) // 正确的输出
.build())
了解 Temperature 对于快速工程至关重要,因为不同的技术受益于不同的 Temperature 设置。
输出长度(MaxTokens)
该 maxTokens 参数限制了模型在响应中可以生成的标记(词片段)的数量。
低值(5-25):适用于单个单词、短语或��分类标签。
中等值(50-500):用于段落或简短解释。
高值(1000+):适用于长篇内容、故事或复杂的解释。
.options(ChatOptions.builder()
.maxTokens(250) // 中等长度的响应
.build())
设置适当的输出长度非常重要,以确保您获得完整的响应而没有不必要的冗长。
采样控制(Top-K 和 Top-P)
这些参数使您可以对生成过程中的令牌选择过程进行细粒度的控制。
Top-K:将 token 的选择范围限制为 K 个最有可能的后续 token。值越高(例如 40-50),多样性越好。
Top-P(核采样):从最小的标记集中动态选择,其累积概率超过 P。0.8-0.95 之类的值很常见。
.options(ChatOptions.builder()
.topK(40) // 仅考虑前 40 个 token
.topP(0.8) // 从覆盖 80% 概率质量的标记中抽样
.build())
这些采样控制与温度协同作用来形成响应特性。
结构化响应格式
除了纯文本响应(使用.content())之外,Spring AI 还可以轻松地使用.entity()方法将 LLM 响应直接映射到 Java 对象。
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment result = chatClient.prompt("...")
.call()
.entity(Sentiment.class);
当与指示模型返回结构化数据的系统提示相结合时,此功能特别强大。
特定于模型的选项
Spring AI 不仅提供了跨不同 LLM 提供程序的一致接口 ChatOptions,还提供了特定于模型的选项类,用于公开特定于提供程序的功能和配置。这些特定于模型的选项允许您利用每个 LLM 提供程序的独特功能。
// 使用 OpenAI 特有的选项
OpenAiChatOptions openAiOptions = OpenAiChatOptions.builder()
.model("gpt-4o")
.temperature(0.2)
.frequencyPenalty(0.5) // OpenAI 特有参数:频率惩罚
.presencePenalty(0.3) // OpenAI 特有参数:存在惩罚
.responseFormat(new ResponseFormat("json_object")) // OpenAI 特有的 JSON 模式
.seed(42) // OpenAI 特有的参数:用于生成确定性结果
.build();
String result = chatClient.prompt("...")
.options(openAiOptions)
.call()
.content();
// 使用 Anthropic 特有的选项
AnthropicChatOptions anthropicOptions = AnthropicChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.2)
.topK(40) // Anthropic 特有参数:用于控制采样多样性
.thinking(AnthropicApi.ThinkingType.ENABLED, 1000) // Anthropic 特有的“思考”配置
.build();
String result = chatClient.prompt("...")
.options(anthropicOptions)
.call()
.content();
每个模型提供商都有其自己的聊天选项实现(例如,OpenAiChatOptions、AnthropicChatOptions、MistralAiChatOptions)这些实现在公开提供商特定参数的同时,仍实现通用接口。这种方法让您可以灵活地使用可移植选项来实现跨提供商兼容性,或者在需要访问特定提供商的独特功能时使用特定于模型的选项。
请注意,使用特定于模型的选项时,您的代码将与该特定提供程序绑定,从而降低可移植性。您需要在访问特定于提供程序的高级功能与在应用程序中保持提供程序独立性之间进行权衡
2,Prompt 工程技术
2.1 零样本提示
零样本提示是指要求人工智能在不提供任何示例的情况下执行任务。这种方法测试模型从零开始理解和执行指令的能力。大型语言模型在海量文本语料库上进行训练,使其能够在没有明确演示的情况下理解“翻译”、“摘要”或“分类”等任务的含义。
零样本训练非常适合一些简单的任务,因为模型在训练过程中很可能已经见过类似的样本,而且您希望尽量缩短提示长度。然而,其性能可能会因任务复杂度和指令的制定方式而有所不同。
public void pt_zero_shot(ChatClient chatClient) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
Sentiment reviewSentiment = chatClient.prompt("""
Classify movie reviews as POSITIVE, NEUTRAL or NEGATIVE.
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. I wish there were more movies like this masterpiece.
Sentiment:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(5)
.build())
.call()
.entity(Sentiment.class);
System.out.println("Output: " + reviewSentiment);
}
此示例展示了如何在不提供示例的情况下对电影评论情绪进行分类。请注意,为了获得更确定的结果,我们采用了较低的温度 (0.1),并且直接.entity(Sentiment.class)映射到 Java 枚举。
参考文献: Brown, TB 等人 (2020)。“语言模型是少样本学习器。”arXiv:2005.14165。https ://arxiv.org/abs/2005.14165
2.2 少样本提示
少样本提示为模型提供了一个或多个示例,以帮助指导其响应,这对于需要特定输出格式的任务特别有用。通过向模型展示所需输入-输出对的示例,它可以学习该模式并将其应用于新的输入,而无需显式更新参数。
单样本训练仅提供单个样本,当样本成本高昂或模式相对简单时非常有用。少样本训练则使用多个样本(通常为 3-5 个),以帮助模型更好地理解更复杂任务中的模式,或展示正确输出的不同变体。
public void pt_one_shot_few_shots(ChatClient chatClient) {
String pizzaOrder = chatClient.prompt("""
Parse a customer's pizza order into valid JSON
EXAMPLE 1:
I want a small pizza with cheese, tomato sauce, and pepperoni.
JSON Response:
{
"size": "small",
"type": "normal",
"ingredients": ["cheese", "tomato sauce", "pepperoni"]
}
EXAMPLE 2:
Can I get a large pizza with tomato sauce, basil and mozzarella.
JSON Response:
{
"size": "large",
"type": "normal",
"ingredients": ["tomato sauce", "basil", "mozzarella"]
}
Now, I would like a large pizza, with the first half cheese and mozzarella.
And the other tomato sauce, ham and pineapple.
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(0.1)
.maxTokens(250)
.build())
.call()
.content();
}
对于需要特定格式、处理边缘情况,或在没有示例的情况下任务定义可能含糊不清的任务,小样本提示尤其有效。示例的质量和多样性会显著影响性能。
参考文献: Brown, TB 等人 (2020)。“语言模型是少样本学习器。”arXiv:2005.14165。https ://arxiv.org/abs/2005.14165
2.3 系统、情境和角色提示
System Prompting
System Prompting 设定了语言模型�的整体背景和目的,定义了模型应该做什么的“总体情况”。它为模型的响应建立了行为框架、约束条件和高级目标,并与具体的用户查询区分开来。
System Prompting 在整个对话过程中充当着持续的“使命”,允许您设置全局参数,例如输出格式、语气、道德界限或角色定义。与专注于特定任务的用户提示不同,System Prompting 框定了所有用户提示的解读方式。
public void pt_system_prompting_1(ChatClient chatClient) {
String movieReview = chatClient
.prompt()
.system("Classify movie reviews as positive, neutral or negative. Only return the label in uppercase.")
.user("""
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. It's so disturbing I couldn't watch it.
Sentiment:
""")
.options(ChatOptions.builder()
.model("claude-3-7-sonnet-latest")
.temperature(1.0)
.topK(40)
.topP(0.8)
.maxTokens(5)
.build())
.call()
.content();
}
System Prompting 与 Spring AI 的实体映射功能结合使用时尤其强大:
record MovieReviews(Movie[] movie_reviews) {
enum Sentiment {
POSITIVE, NEUTRAL, NEGATIVE
}
record Movie(Sentiment sentiment, String name) {
}
}
MovieReviews movieReviews = chatClient
.prompt()
.system("""
Classify movie reviews as positive, neutral or negative. Return
valid JSON.
""")
.user("""
Review: "Her" is a disturbing study revealing the direction
humanity is headed if AI is allowed to keep evolving,
unchecked. It's so disturbing I couldn't watch it.
JSON Response:
""")
.call()
.entity(MovieReviews.class);
System Prompting 对于多轮对话尤其有价值,可确保跨多个查询的一致行为,并建立适用于所有响应的格式约束(如 JSON 输出)。
参考文献: OpenAI。(2022)。“系统消息”。https ://platform.openai.com/docs/guides/chat/introduction
Role Prompting
Role Prompting 会指示模型采用特定的角色或人物,这会影响其生成内容的方式。通过为模型分配特定的身份、专业知识或视角,您可以影响其响应的风格、语气、深度和框架。
Role Prompting 利用模型模拟不同专业领域和沟通风格的能力。常见 role 包括专家(例如,“您是一位经验丰富的数据科学家”)、专业人士(例如,“充当导游”)或风格人物(例如,“像莎士比亚一样解释”)。
public void pt_role_prompting_1(ChatClient chatClient) {
String travelSuggestions = chatClient
.prompt()
.system("""
I want you to act as a travel guide. I will write to you
about my location and you will suggest 3 places to visit near
me. In some cases, I will also give you the type of places I
will visit.
""")
.user("""
My suggestion: "I am in Amsterdam and I want to visit only museums."
Travel Suggestions:
""")
.call()
.content();
}
可以通过样式说明来增强 Role Prompting:
public void pt_role_prompting_2(ChatClient chatClient) {
String humorousTravelSuggestions = chatClient
.prompt()
.system("""
I want you to act as a travel guide. I will write to you about
my location and you will suggest 3 places to visit near me in
a humorous style.
""")
.user("""
My suggestion: "I am in Amsterdam and I want to visit only museums."
Travel Suggestions:
""")
.call()
.content();
}
这种技术对于专业领域知识特别有效,可以在响应中实现一致的语气,并与用户创建更具吸引力、个性化的互动。
参考文献: Shanahan, M. 等人 (2023)。“使用大型语言模型进行角色扮演。”arXiv:2305.16367。https ://arxiv.org/abs/2305.16367
Contextual Prompting
Contextual Prompting 通过传递情境参数为模型提供额外的背景信息。这项技术丰富了模型对具体情境的理解,使其能够提供更相关、更有针对性的响应,而不会扰乱主要指令。
通过提供上下文信息,您可以帮助模型理解与当前查询相关的特定领域、受众、约束或背景事实。这可以带来更准确、更相关、更恰当的响应。
public void pt_contextual_prompting(ChatClient chatClient) {
String articleSuggestions = chatClient
.prompt()
.user(u -> u.text("""
Suggest 3 topics to write an article about with a few lines of
description of what this article should contain.
Context: {context}
""")
.param("context", "You are writing for a blog about retro 80's arcade video games."))
.call()
.content();
}
Spring AI 使用 param() 方法注入上下文变量,使上下文提示更加清晰。当模型需要特定领域知识、根据特定受众或场景调整响应,以及确保响应符合特定约束或要求时,此技术尤为有用。
参考文献: Liu, P. 等 (2021)。“什么是 GPT-3 的良好上下文示例?”arXiv:2101.06804。https: //arxiv.org/abs/2101.06804
2.4 Step-Back Prompting
Step-Back Prompting 通过先获取背景知识,将复杂的请求分解成更简单的步骤。这种技术鼓励模型先从当前问题“后退一步”,思考更广泛的背景、基本原理或与问题相关的常识,然后再处理具体的问题。
通过将复杂问题分解为更易于管理的部分并首先建立基础知识,该模型可以对难题提供更准确的答案。
public void pt_step_back_prompting(ChatClient.Builder chatClientBuilder) {
// 为 chat client 设置通用配置选项
var chatClient = chatClientBuilder
.defaultOptions(ChatOptions.builder()
.model("claude-3-7-sonnet-latest") // 模型名称
.temperature(1.0) // 温度参数,控制生成的随机性
.topK(40) // 采样时考虑的最高概率的前 K 个词
.topP(0.8) // 样本累积概率阈值
.maxTokens(1024) // 最大生成 token 数
.build())
.build();
// 第一步:获取高级概念
String stepBack = chatClient
.prompt("""
Based on popular first-person shooter action games, what are
5 fictional key settings that contribute to a challenging and
engaging level storyline in a first-person shooter video game?
""")
.call()
.content();
// 第二步:将上述概念应用到主要任务中
String story = chatClient
.prompt()
.user(u -> u.text("""
Write a one paragraph storyline for a new level of a first-
person shooter video game that is challenging and engaging.
Context: {step-back}
""")
.param("step-back", stepBack))
.call()
.content();
}
退后提示对于复杂的推理任务、需要专业领域知识的问题以及当您想要更全面、更周到的回应而不是立即得到答案时特别有效。
参考文献: Zheng, Z. 等 (2023)。“退一步思考:在大型语言模型中通过抽象引发推理。”arXiv:2310.06117。https: //arxiv.org/abs/2310.06117
2.5 思维链(COT)
思路链提示鼓励模型逐步推理问题,从而提高复杂推理任务的准确性。通过明确要求模型展示其工作成果或以逻辑步骤思考问题,您可以显著提高需要多步骤推理的任务的性能。
CoT 的工作原理是鼓励模型在得出最终答案之前生成中间推理步骤,类似于人类解决复杂问题的方式。这使得模型的思维过程更加清晰,并有助于其得出更准确的结论。
public void pt_chain_of_thought_zero_shot(ChatClient chatClient) {
String output = chatClient
.prompt("""
When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner?
Let's think step by step.
""")
.call()
.content();
}
public void pt_chain_of_thought_singleshot_fewshots(ChatClient chatClient) {
String output = chatClient
.prompt("""
Q: When my brother was 2 years old, I was double his age. Now
I am 40 years old. How old is my brother? Let's think step
by step.
A: When my brother was 2 years, I was 2 * 2 = 4 years old.
That's an age difference of 2 years and I am older. Now I am 40
years old, so my brother is 40 - 2 = 38 years old. The answer
is 38.
Q: When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step
by step.
A:
""")
.call()
.content();
}
关键词“让我们一步一步思考”会触发模型展示其推理过程。CoT 对于数学问题、逻辑推理任务以及任何需要多步推理的问题尤其有用。它通过明确中间推理来帮助减少错误。
参考文献: Wei, J. 等人 (2022)。“思维链提示在大型语言模型中引发推理。”arXiv:2201.11903。https: //arxiv.org/abs/2201.11903
2.6 自洽性
自洽性是指多次运行模型并汇总结果以获得更可靠的答案。该技术通过对同一问题进行不同的推理路径采样,并通过多数表决选出最一致的答案,解决了 LLM 输出结果的差异性问题。
通过生成具有不同温度或采样设置的多条推理路径,然后聚合最终答案,自洽性可以提高复杂推理任务的准确性。它本质上是一种针对 LLM 输出的集成方法。
public void pt_self_consistency(ChatClient chatClient) {
String email = """
Hi,
I have seen you use Wordpress for your website. A great open
source content management system. I have used it in the past
too. It comes with lots of great user plugins. And it's pretty
easy to set up.
I did notice a bug in the contact form, which happens when
you select the name field. See the attached screenshot of me
entering text in the name field. Notice the JavaScript alert
box that I inv0k3d.
But for the rest it's a great website. I enjoy reading it. Feel
free to leave the bug in the website, because it gives me more
interesting things to read.
Cheers,
Harry the Hacker.
""";
record EmailClassification(Classification classification, String reasoning) {
enum Classification {
IMPORTANT, NOT_IMPORTANT
}
}
int importantCount = 0;
int notImportantCount = 0;
// 使用相同的输入运行模型 5 次
for (int i = 0; i < 5; i++) {
EmailClassification output = chatClient
.prompt()
.user(u -> u.text("""
Email: {email}
Classify the above email as IMPORTANT or NOT IMPORTANT. Let's
think step by step and explain why.
""")
.param("email", email))
.options(ChatOptions.builder()
.temperature(1.0) // Higher temperature for more variation
.build())
.call()
.entity(EmailClassification.class);
// 统计结果
if (output.classification() == EmailClassification.Classification.IMPORTANT) {
importantCount++;
} else {
notImportantCount++;
}
}
// 通过多数票决定最终分类
String finalClassification = importantCount > notImportantCount ?
"IMPORTANT" : "NOT IMPORTANT";
}
对于高风险决策、复杂推理任务以及需要比单一响应更可靠答案的情况,自洽性尤为重要。但其弊端是由于多次 API 调用会增加计算成本和延迟。
参考文献: Wang, X. 等人 (2022)。“自一致性提升语言模型的思路链推理能力。”arXiv:2203.11171。https: //arxiv.org/abs/2203.11171
2.7 思维树(ToT)
思路树 (ToT) 是一种高级推理框架,它通过同时探索多条推理路径来扩展思路链。它将问题解决视为一个搜索过程,模型会生成不同的中间步骤,评估其可行性,并探索最具潜力的路径。
这种技术对于具有多种可能方法的复杂问题或解决方案需要探索各种替代方案才能找到最佳路径的情况特别有效。
public void pt_tree_of_thoughts_game(ChatClient chatClient) {
// Step 1: Generate multiple initial moves
String initialMoves = chatClient
.prompt("""
You are playing a game of chess. The board is in the starting position.
Generate 3 different possible opening moves. For each move:
1. Describe the move in algebraic notation
2. Explain the strategic thinking behind this move
3. Rate the move's strength from 1-10
""")
.options(ChatOptions.builder()
.temperature(0.7)
.build())
.call()
.content();
// 步骤 2:评估并选择最有希望的举动
String bestMove = chatClient
.prompt()
.user(u -> u.text("""
Analyze these opening moves and select the strongest one:
{moves}
Explain your reasoning step by step, considering:
1. Position control
2. Development potential
3. Long-term strategic advantage
Then select the single best move.
""").param("moves", initialMoves))
.call()
.content();
// 步骤 3:从最佳走法探索未来的游戏状态
String gameProjection = chatClient
.prompt()
.user(u -> u.text("""
Based on this selected opening move:
{best_move}
Project the next 3 moves for both players. For each potential branch:
1. Describe the move and counter-move
2. Evaluate the resulting position
3. Identify the most promising continuation
Finally, determine the most advantageous sequence of moves.
""").param("best_move", bestMove))
.call()
.content();
}
参考文献: Yao, S. 等 (2023)。“思维树:基于大型语言模型的深思熟虑的问题求解”。arXiv:2305.10601。https: //arxiv.org/abs/2305.10601
2.8 自动提示工程
自动提示工程利用人工智能生成并评估备选提示。这项元技术利用语言模型本身来创建、改进和基准测试不同的提示变体,以找到特定任务的最佳方案。
通过系统地生成和评估提示语的变化,APE 可以找到比人工设计更有效的提示语,尤其是在处理复杂任务时。这是��利用 AI 提升自身性能的一种方式。
public void pt_automatic_prompt_engineering(ChatClient chatClient) {
// 生成相同请求的变体
String orderVariants = chatClient
.prompt("""
We have a band merchandise t-shirt webshop, and to train a
chatbot we need various ways to order: "One Metallica t-shirt
size S". Generate 10 variants, with the same semantics but keep
the same meaning.
""")
.options(ChatOptions.builder()
.temperature(1.0) // 高温激发创造力
.build())
.call()
.content();
// 评估并选择最佳变体
String output = chatClient
.prompt()
.user(u -> u.text("""
Please perform BLEU (Bilingual Evaluation Understudy) evaluation on the following variants:
----
{variants}
----
Select the instruction candidate with the highest evaluation score.
""").param("variants", orderVariants))
.call()
.content();
}
APE 对于优化生产系�统的提示、解决手动提示工程已达到极限的挑战性任务以及系统地大规模提高提示质量特别有价值。
参考文献: Zhou, Y. 等 (2022)。“大型语言模型是人类级别的快速工程师。”arXiv:2211.01910。https ://arxiv.org/abs/2211.01910
2.9 代码提示
代码提示是指针对代码相关任务的专门技术。这些技术利用法学硕士 (LLM) 理解和生成编程语言的能力,使他们能够编写新代码、解释现有代码、调试问题以及在语言之间进行转换。
有效的代码提示通常包含清晰的规范、合适的上下文(库、框架、代码规范),有时还会包含类似代码的示例。为了获得更确定的输出,温度设置通常较低(0.1-0.3)。
public void pt_code_prompting_writing_code(ChatClient chatClient) {
String bashScript = chatClient
.prompt("""
Write a code snippet in Bash, which asks for a folder name.
Then it takes the contents of the folder and renames all the
files inside by prepending the name draft to the file name.
""")
.options(ChatOptions.builder()
.temperature(0.1) // 确定性代码的低温
.build())
.call()
.content();
}
public void pt_code_prompting_explaining_code(ChatClient chatClient) {
String code = """
#!/bin/bash
echo "Enter the folder name: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "Folder does not exist."
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "Files renamed successfully."
""";
String explanation = chatClient
.prompt()
.user(u -> u.text("""
Explain to me the below Bash code:
` ` `
{code}
` ` `
""").param("code", code))
.call()
.content();
}
public void pt_code_prompting_translating_code(ChatClient chatClient) {
String bashCode = """
#!/bin/bash
echo "Enter the folder name: "
read folder_name
if [ ! -d "$folder_name" ]; then
echo "Folder does not exist."
exit 1
fi
files=( "$folder_name"/* )
for file in "${files[@]}"; do
new_file_name="draft_$(basename "$file")"
mv "$file" "$new_file_name"
done
echo "Files renamed successfully."
""";
String pythonCode = chatClient
.prompt()
.user(u -> u.text("""
Translate the below Bash code to a Python snippet:
{code}
""").param("code", bashCode))
.call()
.content();
}
代码提示对于自动化代码文档、原型设计、学习编程概念以及编程语言间的转换尤其有用。将其与少样本提示或思路链等技术结合使用,可以进一步提升其有效性。
参考文献:Chen, M. 等人 (2021)。“评估基于代码训练的大型语言模型。”arXiv:2107.03374。https ://arxiv.org/abs/2107.03374
结论
Spring AI 提供了优雅的 Java API,用于实现所有主要的即时工程技术。通过将这些技术与 Spring 强大的实体映射和流畅的 API 相结合,开发人员可以使用简洁、可维护的代码构建复杂的 AI 应用。
最有效的方法通常需要结合多种技术——例如,将系统提示与少量样本示例结合使用,或将思路链与角色提示结合使用。Spring AI 灵活的 API 使这些组合易于实现。
对于生产应用程序,请记住:
使用不同参数(温度、top-k、top-p)测试提示
考虑使用自我一致性进行关键决策
利用 Spring AI 的实体映射实现类型安全的响应
使用上下文提示来提供特定于应用程序的知识
借助这些技术和 Spring AI 强大的抽象,您可以创建强大的 AI 驱动应用程序,提供一致、高质量的结果。
参考
-
Brown, T. B., et al. (2020). "Language Models are Few-Shot Learners." arXiv:2005.14165.
-
Wei, J., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." arXiv:2201.11903.
-
Wang, X., et al. (2022). "Self-Consistency Improves Chain of Thought Reasoning in Language Models." arXiv:2203.11171.
-
Yao, S., et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." arXiv:2305.10601.
-
Zhou, Y., et al. (2022). "Large Language Models Are Human-Level Prompt Engineers." arXiv:2211.01910.
-
Zheng, Z., et al. (2023). "Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models." arXiv:2310.06117.
-
Liu, P., et al. (2021). "What Makes Good In-Context Examples for GPT-3?" arXiv:2101.06804.
-
Shanahan, M., et al. (2023). "Role-Play with Large Language Models." arXiv:2305.16367.
-
Chen, M., et al. (2021). "Evaluating Large Language Models Trained on Code." arXiv:2107.03374.
-
Spring AI Documentation
-
ChatClient API Reference
-
Google’s Prompt Engineering Guide